1. 컬렉션 프레임워크
: 데이터 군을 저장하는 클래스들을 표준화한 설계
>>컬렉션 프레임웤의 3가지 인터페이스

=> Collection : List와 Set의 공통된 부분을 뽑아 정의한 인터페이스

>> Collection 인터페이스의 메서드

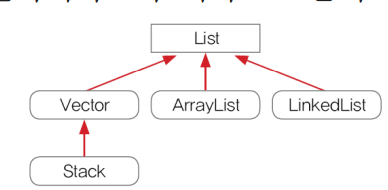
>>List 인터페이스
: 순서 존재 + 중복허용
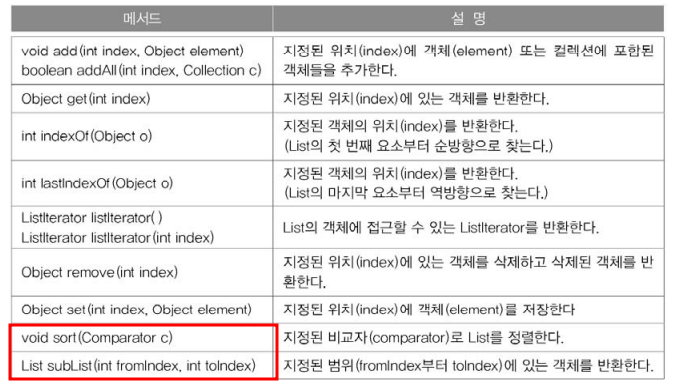
-- 메서드
>>Set인터페이스
: 순서x + 중복 x

>>Map 인터페이스
-- 키와 값을 하나의 쌍으로 묶어서 저장
- 키는 중복이 불가/ 값은 중복이 가능
- 순서가 존재x

ㅡMap.Entry 인터페이스
: Map 인터페이스의 내부 인터페이스
: key-value 쌍을 다루기 위한 인터페이스
| 메서드 | 설명 |
| boolean equals(Object o) | 동일한 Entry인지 확인 |
| Object getKey() | Entry의 key 객체를 반환 |
| Object getValue() | Entry의 value 객체를 반환 |
| int hashCode() | Entry의 해시코드를 반환 |
| Object setValue(Object value) | value 값을 갱신 |
2. ArrayList
: List 인터페이스를 구현하기 때문에 저장순서가 유지되고 중복을 허용
: Vector를 개선하였기에 기능적으로 동일
: 더이상 저장할 공간이 없으면 새로운 배열을 생성해서 복사한 다음 저장됨
-- 생성자
| ArrayList() | 크기가 10인 ArrayList를 생성 |
| ArrayList(Collection c) | 주어진 컬렉션이 저장된 ArrayList를 생성 |
| ArrayList(int Capacity) | 지정된 초기용량을 갖는 ArrayList 생성 |
--메서드
| 메서드 | 설명 |
| boolean add(Object o) void add(int idx, Object o) |
ArrayList의 마지막에 객체를 추가 / 성공하면 true idx에 o를 추가 |
| Object remove(int index) boolean remove(Object o) |
지정된 위치에 있는 객체를 제거 지정한 객체를 제거 / 성공하면 true |
| boolean addAll(Collection c) boolean addAll(int idx, Collection c) |
Collection c의 모든 요소를 객체에 저장 주어진 위치부터 Collection의 요소들을 저장 |
| boolean removeAll(Collection c) | 지정한 컬렉션에 저장된 것과 동일한 객체들을 ArrayList에서 제거 |
| void clear() | ArrayList를 비우기 |
| Object clone() | ArrayList를 복제 |
| boolean contains(Object o) | 객체 o가 ArrayList에 들어있는지 확인 |
| void ensureCapacity(int minCapacity) | ArrayList의 용량이 최소한 minCapacity가 되도록 한다. |
| Object get(int index) | 지정된 위치에 저장된 객체를 반환 |
| int indexOf(Object o) int lastIndexOf(Object o) |
지정된 객체가 저장된 위치를 찾아 반환 |
| boolean isEmpty() | ArrayList가 비어있는지 확인 |
| Iterator iterator() | ArrayList의 iterator를 반환 |
| ListIterator listIterator() ListIterator listIterator(index) |
ArrayList의 ListIterator를 반환 ArrayList의 index에서부터 시작되는 ListIterator를 반환 |
| boolean retainAll(Collection c) | Collection에 저장된 객체와 공통된 것들만 남기고 ArrayList의 나머지 객체를 삭제 |
| Object set(int idx, Object element) | element를 index에 저장 |
| int size() | 저장된 객체의 개수 반환 |
| void sort(Comparator c) | 지정된 정렬기준으로 ArrayList 정렬 |
| List subList(int fromindex, int toindex) | fromIndex부터 toIndex까지 저장된 객체를 반환 |
| Object [] toArray() | ArrayList에 저장된 모든 객체를 객체배열로 반환 |
| Object [] toArray(Object [] a) | ArrayList에 저장된 모든 객체들을객체배열 a에 담아 반환 |
| vid trimToSize() | 용량을 크기에 맞게 줄임(빈공간 삭제) |
ex)
public class ArrayListEx2 {
public static void main(String[] args) {
ArrayList list1 = new ArrayList(10);
list1.add(5);
list1.add(4);
list1.add(2);
list1.add(0);
list1.add(1);
list1.add(3);
ArrayList list2= new ArrayList(list1.subList(1,4));
print(list1, list2);
//list1 : [0, 1, 2, 3, 4, 5]
//list2 : [0, 2, 4]
Collections.sort(list1);
Collections.sort(list2);
print(list1, list2);
//list1 : [5, 4, 2, 0, 1, 3]
//list2 : [4, 2, 0]
System.out.println("list1.containsAll(list2) : "+ list1.containsAll(list2));
list2.add("B");
list2.add("C");
list2.add(3,"A");
print(list1, list2);
//list1.containsAll(list2) : true
//list1 : [0, 1, 2, 3, 4, 5]
//list2 : [0, 2, 4, A, B, C]
list2.set(3, "AA");
print(list1, list2);
//list1 : [0, 1, 2, 3, 4, 5]
//list2 : [0, 2, 4, AA, B, C]
//list1과 list2와 겹치는 부분만 남기고 나머지는 삭제
System.out.println("list1.retainAll(list2) : "+ list1.retainAll(list2) );
print(list1, list2);
//list1.retainAll(list2) : true
//list1 : [0, 2, 4]
//list2 : [0, 2, 4, AA, B, C]
//list2에서 list1에 포함된 객체들을 삭제함
for(int i=list2.size()-1; i>=0 ;i--){
if(list1.contains(list2.get(i)))
list2.remove(i);
}
print(list1, list2);
//list1 : [0, 2, 4]
//list2 : [AA, B, C]
}
static void print(ArrayList list1, ArrayList list2){
System.out.println("list1 : "+ list1);
System.out.println("list2 : "+ list2);
System.out.println();
}
}
3. LinkedList
>>ArrayList의 장단점
-- 장점
: 데이터를 읽고 저장하는데 시간이 적음
--단점
1) 크기 변경이 불가 : 용량변경시 새로운 인스턴스 생성해야 함
2) 비순차적 데이터 추가 삭제에 시간이 많이 걸림
: 데이터를 추가 삭제하기 위해 다른 데이터를 옮겨야 함(정렬 시)
>>ArrayList vs LinkedList

- 순차적 추가/ 삭제 => ArrayList가 빠름
- 중간 데이터 추가/삭제 => LinkedList가 빠름
- 접근 시간 => ArrayList가 빠름
--arrayList : 배열의 주소 + n*데이터 타입의 크기
--LinkedList : 주소를 바로 얻지 못하고 순차적으로 따라가야 함
package ch11;
import java.util.*;
public class ArrayListLinkedListTest {
public static void main(String[] args) {
ArrayList al = new ArrayList(2000000);
LinkedList ll= new LinkedList();
System.out.println("=순차적으로 추가하기=");
System.out.println("ArrayList : "+ add1(al));
System.out.println("LinkedList : "+ add1(ll));
System.out.println();
System.out.println("=중간에서 추가하기=");
System.out.println("ArrayList : "+ add2(al));
System.out.println("LinkedList : "+ add2(ll));
System.out.println();
System.out.println("=중간에서 삭제하기=");
System.out.println("ArrayList : "+ remove2(al));
System.out.println("LinkedList : "+ remove2(ll));
System.out.println();
System.out.println("=순차적으로 삭제하기=");
System.out.println("ArrayList : "+ remove1(al));
System.out.println("LinkedList : "+ remove1(ll));
}
public static long add1(List list){
long start = System.currentTimeMillis();
for(int i=0; i<1000000; i++) list.add(i+"");
long end= System.currentTimeMillis();
return end-start;
}
public static long add2(List list){
long start = System.currentTimeMillis();
for(int i=0; i<1000000; i++) list.add(500,"X");
long end= System.currentTimeMillis();
return end-start;
}
public static long remove1(List list){
long start = System.currentTimeMillis();
for(int i=list.size()-1; i>=0; i--) list.remove(i);
long end= System.currentTimeMillis();
return end-start;
}
public static long remove2(List list){
long start = System.currentTimeMillis();
for(int i=0; i<10000; i--) list.remove(i);
long end= System.currentTimeMillis();
return end-start;
}
}
>> 실행결과
=순차적으로 추가하기=
ArrayList : 161
LinkedList : 398
=중간에서 추가하기=
ArrayList : 3742
LinkedList : 29
=중간에서 삭제하기=
ArrayList : 3451
LinkedList : 259
=순차적으로 삭제하기=
ArrayList : 13
LinkedList : 50
1.4 Stack과 Queue
>>스택과 큐
-스택 : LIFO 구조(마지막에 저장된 것을 제일 먼저 꺼냄)
- 큐 : FIFO구조 (처음 저장된 것을 가장 먼저 꺼냄)

=> Stack : ArrayList로 구현하는 것이 좋음
=> Queue : 맨 처음 index를 삭제하므로 LinkedList가 적합
>>Stack 메서드
| 메서드 | 설명 |
| boolean empty() | Stack이 비었는지 확인 |
| Object peek() | 가장 위에 저장된 객체를 반환(삭제x), 비었다면 EmptyStackException발생 |
| Object pop() | 맨 위에 저장된 객체 반환(삭제0) , 비었다면 EmptyStackException 발생 |
| Object push(Object item) | Stack에 객체(item)을 저장 |
| int serach(Object o) | Stack에서 주어진 객체를 찾아서 그 위치를 반환, 못찾으면 -1을 반환 |
>>Queue 메서드
| 메서드 | 설명 |
| bollean add(Object o) | 지정된 객체를 Queue에 추가 |
| Object remove() | Queue에서 객체를 꺼내 반환 비어 있으면 NoSuchElementException발생 |
| Object element() | 삭제 없이 요소를 읽어온다. peek와 달리 Queue가 비었을 때 NoSuchElementException 발생 |
| boolean offer(Object o) | Queue 객체를 저장, 성공하면 true, 실패하면 false를 반환 |
| Object poll() | Queue에서 객체를 꺼내서 반환 비어있으면 null반환 |
| Object peek() | 삭제 없이 요소를 읽어옴/ Queue가 비어있으면 null 반환 |
package ch11;
import java.util.*;
public class StackQueueEx {
public static void main(String[] args) {
Stack st= new Stack();
Queue q= new LinkedList();
st.push("0");
st.push("1");
st.push("2");
q.offer("0");
q.offer("1");
q.offer("2");
System.out.println("=Stack =");
while(!st.empty()){
System.out.println(st.pop());
}
System.out.println("=Queue=");
while(!q.isEmpty())
System.out.println(q.poll());
}
}
>>실행결과
=Stack =
2
1
0
=Queue=
0
1
2
=> Stack : 클래스로 구현하여 제공
=> Queue: 인터페이스만 제공하고 구현 클래스는 제공x => 인터페이스를 구현한 클래스를 사용하면 됨
>>우선순위 큐
- 우선순위가 높은 것부터 꺼내게 됨
- null은 저장 불가
- heapq이라는 자료구조로 저장
package ch11;
import java.util.*;
public class PriorityQueue {
public static void main(String[] args) {
Queue pq = new PriorityQueue();
pq.offer(3);
pq.offer(1);
pq.offer(5);
pq.offer(2);
pq.offer(4);
System.out.println(pq);
Object obj= null;
while((obj=pq.poll()) !=null){
System.out.println(obj);
}
}
}
>>Deque()
- Stack과 Queue의 결합
- 양끝에서 저장과 삭제가 가능함(offerFirst/offerLast + pollFirst/pollLast)
- 구현클래스 : ArrayDeque or LinkedList

'기술 서적 > 자바의 정석' 카테고리의 다른 글
| [자바의 정석] ch11-3.컬렉션 프레임워크 : HashMap/TreeMap / Collections (0) | 2024.01.20 |
|---|---|
| [자바의 정석] 11-2.컬렉션 프레임워크 : iterator / Arrays / Comparator / Set (0) | 2024.01.16 |
| [자바의 정석] ch9-1. java.lang 패키지와 유용한 클래스 (0) | 2024.01.09 |
| [자바의 정석] ch8. 예외처리 (1) | 2024.01.06 |
| [자바의 정석] ch7. 객체지향 프로그래밍 II (0) | 2024.01.05 |



