해당 내용은 인프런 강의 [대규모 트래픽 처리를 위한 부하테스트 입문/실전]을 듣고 개인적인 공부 목적으로 핵심적인 내용을 정리한 요약본입니다. 자세한 원리 혹은 개념 설명이 궁금하시다면 강의를 참고하시는 것을 권장드립니다.
부하테스트란?
: 시스템의 트래픽 수용량을 테스트하는 것
주요 측정량
1) 처리량(Throughput)
: 1초당 처리할 수 있는 트래픽 양
: 단위 TPS(Transaction Per Seconds) : 1초당 처리한 트랙잭션의 수
2) 지연 시간(Latency)
: 요청에 대한 응답 시간
ex) latency가 2.5초이다. == 하나의 API에 요청을 보내고 응답을 받기까지 2.5초가 걸렸다
병목지점
전체 시스템에서 특정 서버자원(CPU, Memory 등)이 한계에 도달해 전체 성능이 저하되는 구간
✅ ’병목 지점의 Throughput’이 곧 ‘전체 Throughput’이다.

병목 구간인 B-C 1시간에 300대만 통과할 수 있기 때문에. A-B 구간에서 아무리 1시간에 1000대를 통과시켜도 전체 ThrouhPut은 300대가 된다.
✅ 특정 병목 지점을 해소하면 다른 곳에서 새로운 병목 지점이 발생한다.
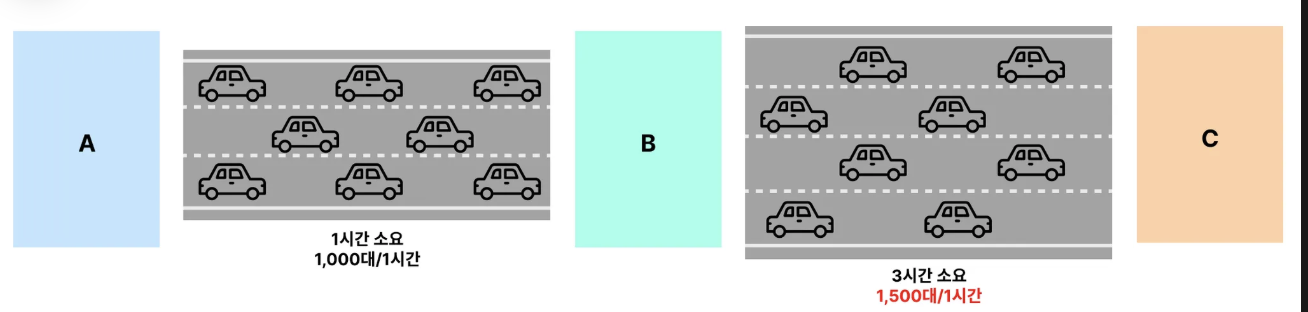
위에 있는 시스템에서 B-C의 성능을 개선하여 1시간에 1500대가 통과가능하도록 ThroughPut을 개선하였다.
이제 병목지점은 A-B가 된다. 따라서 A-B의 Throughput인 1000대가 전체 처리량이 된다.
즉, 병목지점은 상대적으로 결정되므로, 하나의 병목지점을 해소하면 다른 곳이 새로운 병목지점이 된다.
부하 테스트의 전체 흐름
1) 부하 테스트의 필요성 인식
2) 부하테스트의 목표 설정하기(처리량 + 지연시간) ex) 처리량 : 2000TPS, 평균 Latency : 800ms
3) 1차 부하테스트 진행 : 현재 시스템의 한계 트래픽은?
4) 병목 지점 파악 후 개선
5) 2차 부하테스트 진행 : 개선한 시스템의 한계 트래픽은?
주의점
1) 적절한 부하테스트 시간
- 1분간격으로 기록되는 모니터링 도구를 가지고 성능측정을 위해 최소 5분간의 부하테스트 진행
2) 프로덕션 환경과 비슷한 데이터 세팅
- 데이터베이스는 데이터가 어떻게 저장되어 있는지와 얼마나 많은 양이 저장되어 있는지에 따라 성능차이가 많이 남.
3) 프로덕션과 분리된 환경에서 테스트
- 프로덕션 환경에서 부하테스트를 하면 안됨
4) 부하 테스트 환경 독립적으로 분리하기
- 부하테스트 툴 자체도 트래픽을 만들어내면서 컴퓨팅 리소스(CPU, 메모리를 사용함)
5) 부하 테스트 툴을 개인 컴퓨터에 설치하지 않기
- 컴퓨터 자체적으로 부하를 발생시킬 때 제한이 걸릴 때가 있음
- 따라서 EC2 인스턴스를 생성해 Linux 환경에서 부하테스트를 진행할 것을 권장함.
실습 아키텍쳐
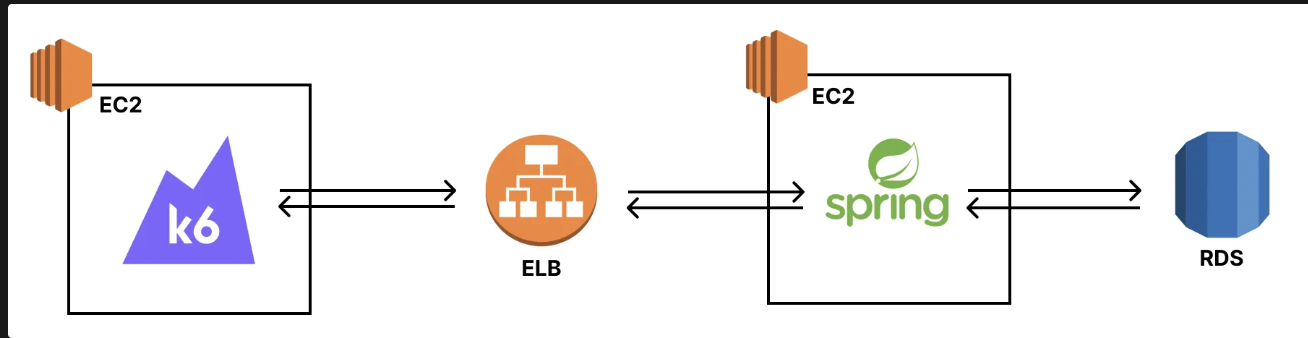
> k6 인스턴스 세팅
os : ubuntu
아키텍처 : 64비트(x86)
인스턴스 유형 : t3a.small (부하 발생을 위한 리소스 규모를 고려)
대시보드 모니터링을 위한 보안그룹 규칙 추가
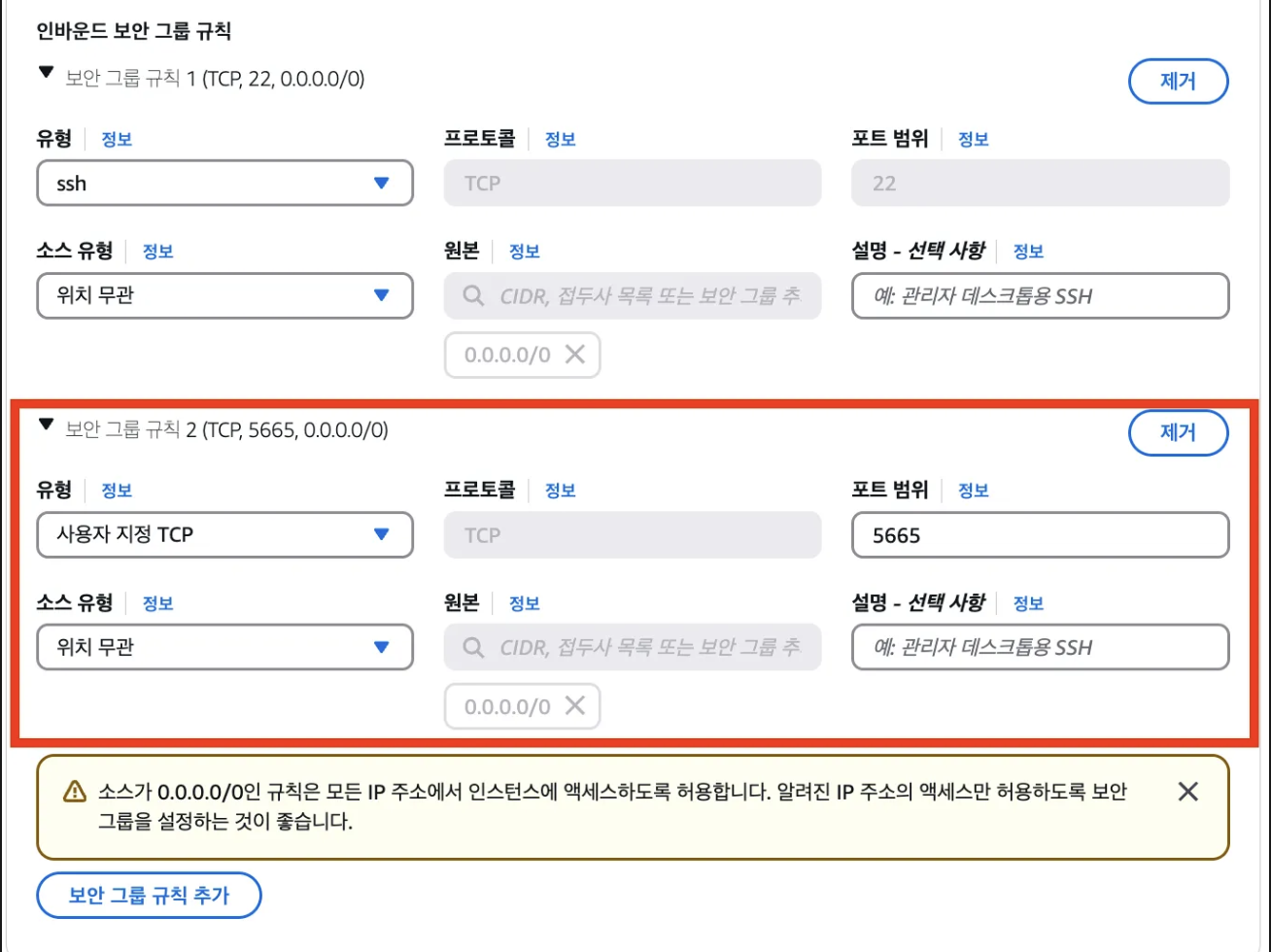
k6 설치
$ sudo gpg -k && /
sudo gpg --no-default-keyring --keyring /usr/share/keyrings/k6-archive-keyring.gpg --keyserver hkp://keyserver.ubuntu.com:80 --recv-keys C5AD17C747E3415A3642D57D77C6C491D6AC1D69 && /
echo "deb [signed-by=/usr/share/keyrings/k6-archive-keyring.gpg] https://dl.k6.io/deb stable main" | sudo tee /etc/apt/sources.list.d/k6.list && /
sudo apt-get update && /
sudo apt-get install k6
설치 확인
k6
EC2 인스턴스 세팅
os : ubuntu
아키텍처 : 64비트(x86)
인스턴스 유형 : t3a.small
보안그룹 : 인터넷에서 HTTP 트래픽 허용 체크
1. jdk 설치(Spring Boot 3.x.x 버전 사용 예정 + JDK는 17버전 사용 예정)
$ sudo apt update
$ sudo apt install openjdk-17-jdk
$ java -version //잘 설치되었는지 확인
2. 프로젝트 클론 받기
$ git clone https://github.com/JSCODE-COURSE/load-testing-server.git
3. application.yml에 RDS 설정하기
- ~/load-testing-server/src/main/resources/application.yml
server:
port: 80
spring:
datasource:
url: jdbc:mysql://{RDS 주소}:3306/jscode
username: admin
password: {비밀번호}
driver-class-name: com.mysql.cj.jdbc.Driver
jpa:
hibernate:
ddl-auto: create
4. 서버 빌드 및 실행
$ cd ~/load-testing-server
$ ./gradlew clean build -x test
$ cd build/libs
$ sudo nohup java -jar jscode-0.0.1-SNAPSHOT.jar & //백그라운드 실행
5. 잘 실행되고 있는지 확인
5-1) 80포트에서 잘 실행되고 있는지 프로세스 확인
$ sudo lsof -i:80
5-2) EC2 -ip주소로 접속해보기

> RDS 세팅하기
- 표준생성
- 엔진 : MySQL
- 템플릿 : 프리 티어
- 마스터 암호 설정
- 인스턴스 구성 : db.t4g.micro
- 퍼블릭 엑세스 : yes
- 보안그룹
- 인바운드 : MYSQL/Aurora 모든 트래픽 허용(0.0.0.0/0)
- 초기 데이터베이스 이름 지정 : ex) coli
> 잘 접속되는지 DataGrip으로 확인하기
- host: rds 엔트리 포인트 적기
- user : admin (사용자 이름)
- password : admin 마스터 비밀번호 적기

> ELB 세팅하기
- 유형 : ALB
- 가용 영역 : ap-northeast-2a, 2b, 2c, 2d 모두 허용하기
- 보안그룹 생성
- 인바운드 규칙 : HTTP 모든 트래픽 허용
- 대상 그룹을 EC2를 향하도록 설정하기
- 인스턴스 유형
- 상태 검사 : /health
✅ k6를 활용해 부하테스트 진행하기
step1. 프로덕션 환경과 비슷하게 구성하기 위해 더미 데이터 넣기
- 100만개의 게시글 데이터 세팅
-- 높은 재귀(반복) 횟수를 허용하도록 설정
-- (아래에서 생성할 더미 데이터의 개수와 맞춰서 작성하면 된다.)
SET SESSION cte_max_recursion_depth = 1000000;
-- 더미 데이터 삽입 쿼리
INSERT INTO boards (content, title, created_at)
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 1000000 -- 생성하고 싶은 더미 데이터의 개수
)
SELECT
CONCAT('Content', LPAD(n, 7, '0')), -- 'Content' 다음에 7자리 숫자로 구성된 이름 생성
CONCAT('Title', LPAD(n, 7, '0')), -- 'Title' 다음에 7자리 숫자로 구성된 이름 생성
TIMESTAMP(DATE_SUB(NOW(), INTERVAL FLOOR(RAND() * 3650) DAY) + INTERVAL FLOOR(RAND() * 86400) SECOND) AS created_at -- 최근 10년 내의 임의의 날짜와 시간 생성
FROM cte;
-- 잘 생성됐는 지 확인
SELECT COUNT(*) FROM boards;
step2. k6 스크립트 작성
- 100명의 사용자 중 95명은 게시글 조회(GET /boards)를 하고, 5명이 게시글 작성(POST /boards)를 한다고 가정
import http from 'k6/http'; //http api 호출을 위한 import
import { sleep } from 'k6' //호출 간격을 두기 위한 sleep import
export const options ={
//부하를 생성하는 stages 설정
stages: [
//10분에 걸쳐 vus(가상 유저 수)가 50도 도달
{ duration: '10m', target: 50 }
],
};
export default function() {
let random = Math.random();
//100명 중 5명의 비율로 게시글을 작성
if(random < 0.05) {
const data = {title: '제목', content: '내용' }; //request body
http.post('http://{ELB 주소}/boards', JSON.stringify(data), {
headers: { 'Content-Type': 'application/json' },
});
} else {
//100명 중 95명은 게시글 조회
http.get('http://{ELB 주소}/boards');
}
//1초 휴식 -> 안하면 계속 반복 요청 보내게 됨
sleep(1);
}
step3. 부하 테스트 시작하기
$ K6_WEB_DASHBOARD=true k6 run script.js

step4. 결과 해석하기
http://{k6가 실행되고 있는 EC2 IP 주소} :5665 로 대시보드를 연다
해석포인트 1. 가상 유저 수에 따라 더이상 증가하지 않는 ThroughPut을 파악한다.
http_reqs / http_rate (ThroughPut): VUs가 늘어나도 더이상 증가하지 않는 HTTP Request Rate 가 현재 시스템의 최대 처리량이다
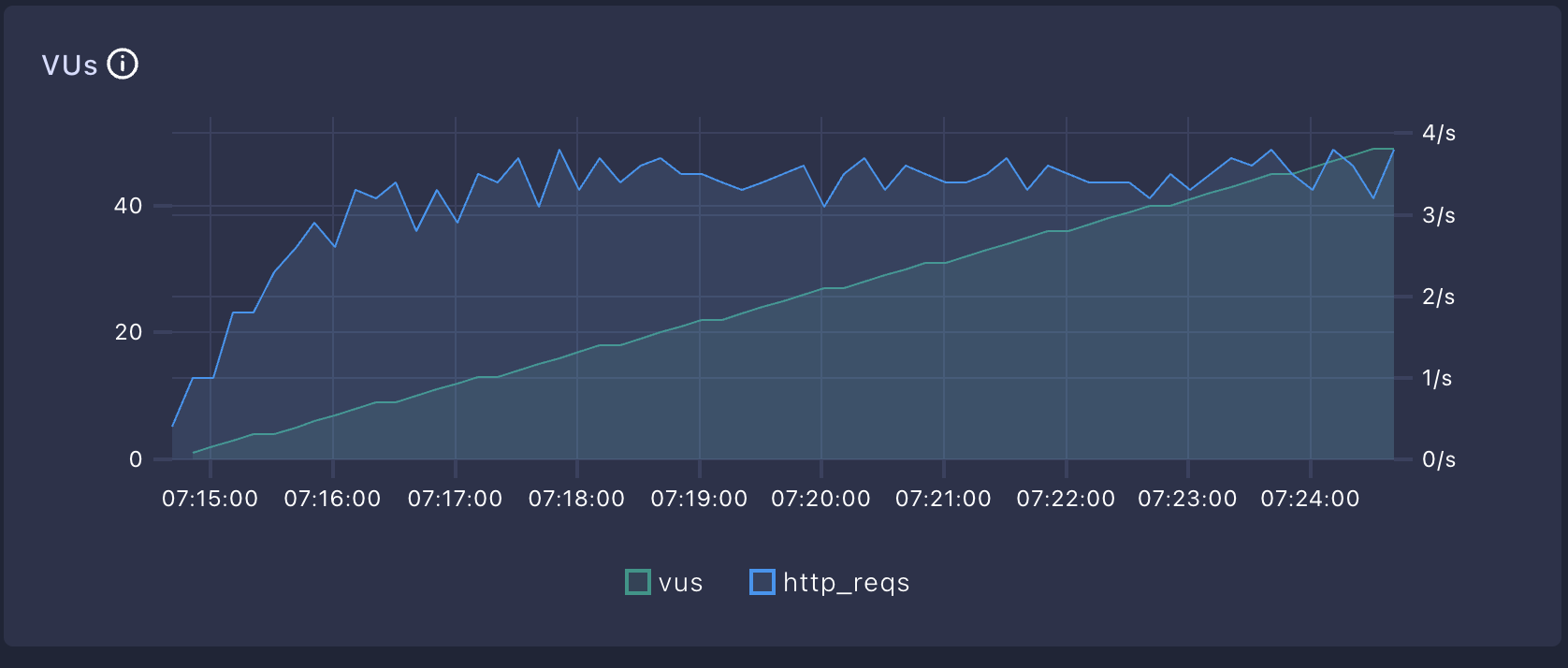
-> 가상유저수가 아무리 늘어나도 3 TPS 정도를 유지하고 있는 모습을 볼 수 있다.
해석 포인트 2. HTTP Request Duration이 비이상적으로 높은 것은 아닌지 체크한다.

-> 처리량이 한계치에 다다르기 전에 1s이하의 응답속도를 보장하고 있다.
해석포인트 3. 실패한 API call이 있는지 failed의 비율을 파악한다.

-> Http Request Failed가 0인것으로 보아 실패한 요청은 없음을 알 수 있다.
모니터링 세팅하기
다시 인프라 구조를 바라보자
현재 TPS는 3정도 나오는 상황에서 목표 TPS인 8을 달성하기 위해서는 병목지점을 파악할 필요가 있다. 모니터링 세팅을 통해 어떤 부분이 병목지점인지를 파악해보자
EC2 모니터링 셋팅하기
EC2 기본 수집 지표
- CPU 사용률
- 네트워크 사용률
- 디스크 성능
- 디스크 읽기/ 쓰기
- 등등
EC2에 CloudWatch Agent 세팅하기
1. IAM Role 생성
- IAM > 역할 > 역할 생성
- 신뢰할 수 있는 엔티티 유형 : AWS 서비스
- 사용 사례 : EC2
- 권한 추가 : cloudwathagentserverPolicy
2. EC2 인스턴스에 IAM Role 연결
인스턴스 > 작업> 보안 > IAM 역할 수정 > 생성했던 IAM 역할 수정

3. EC2 인스턴스로 접속해 Cloudwatch Agent 설치하기
# Ubuntu x86-64 Cloudwatch Agent 다운로드
$ wget https://s3.amazonaws.com/amazoncloudwatch-agent/ubuntu/amd64/latest/amazon-cloudwatch-agent.deb
# 다운받은 패키지 설치
$ sudo dpkg -i -E ./amazon-cloudwatch-agent.deb
4. 설정 파일 생성하기
$ sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-config-wizard
5. Cloudwatch Agent 실행하기
$ sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -s -c file:/opt/aws/amazon-cloudwatch-agent/bin/config.json
6. 세부 모니터링 설정
EC2는 기본 5분 간격으로 매트릭을 수집한다.
1분 간격으로 메트릭을 수집하게끔 바꾸어보자
EC2 설정 페이지 > 모니터링 > 세부 모니터링 관리

세부 모니터링 체크

RDS 모니터링 셋팅하기 -> 기본 지표 사용
기본 수집 지표
- CPU 사용률
- FreeableMemory(사용 가능한 메모리 용량)
모니터링 대시보드 구축하기
- EC2와 RDS의 CPU 사용률, 메모리 사용률을 한눈에 볼 수 있도록 셋팅하기
1. CloudWatch > 대시보드 > 대시보드 생성 > 위젯추가
2. Ec2 CPU 사용률 추가하기

- 위젯 추가 : 행
- aws 네임 스페이스 : EC2
- 지표 : 인스턴스별 지표
- 지표 그래프 추가 : cpuutilization,
- 그래프로 표시된 지표 : 기간 1분으로 설정
3. EC2- 메모리 사용률 추가
- 위젯 유형 : 행
- 사용자 지정 네임스페이스 : CWAgent
- 지표 : InstanceId
- 지표 그래프 추가 : mem_used_percent
4. RDS - CPU 사용률 /사용가능한 메모리 추가하기
- 위젯 유형 : 행
- aws 네임스페이스 : RDS
- 지표 : DBInstanceIndentifier
- 지표 그래프 추가 : cpuutilization, FreeableMemory
이제 4가지 지표를 한눈에 볼 수 있는 대시보드를 만들었다.

대시보드로 병목지점 진단하기
이제 대시보드를 통해 각 자원의 소모량과 함게 어떤 부분이 병목지점인지 알아챌 수 있게 되었다. 대시보드와 함께 부하테스트를 다시 실행해보자.
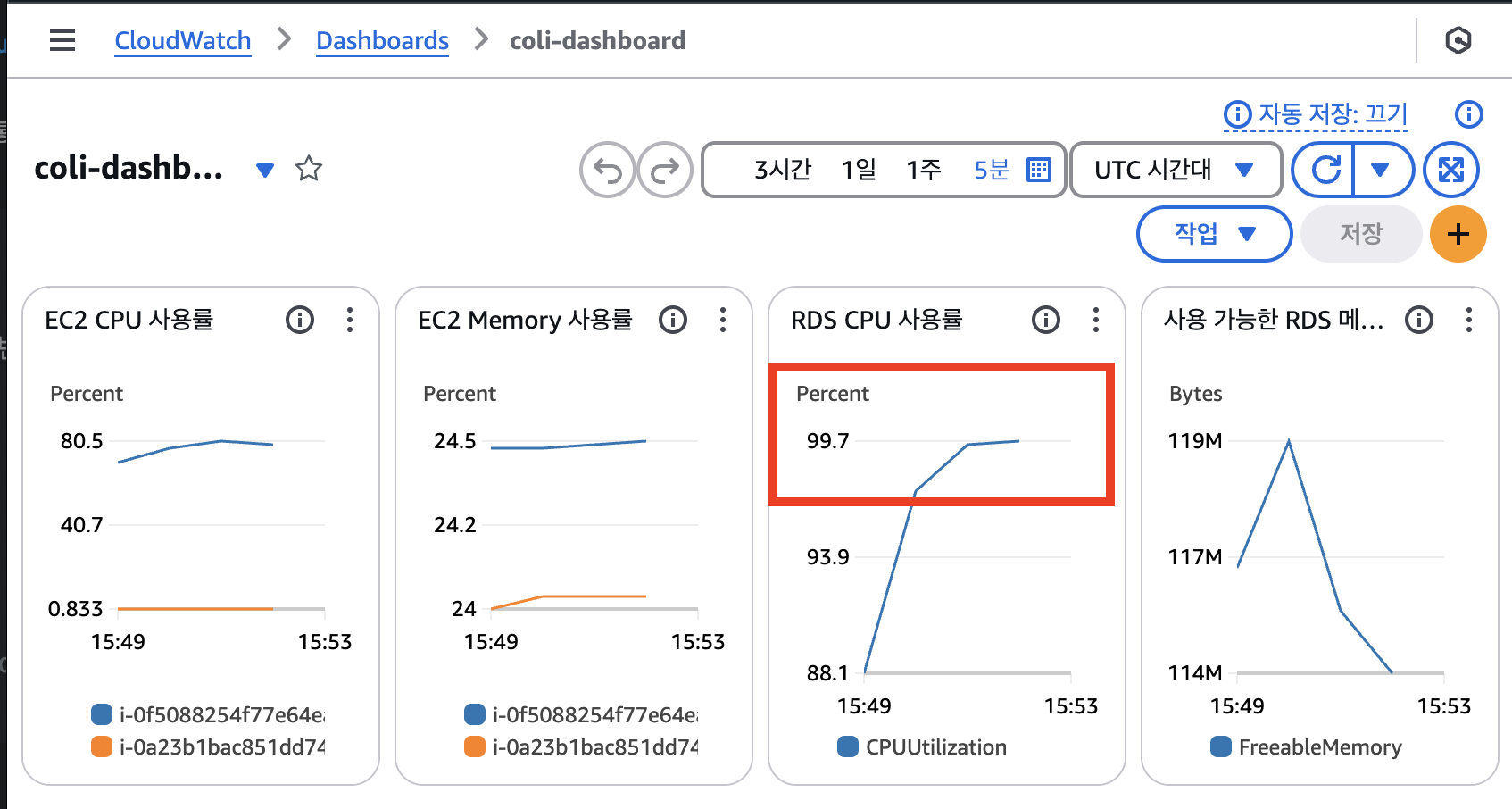
모니터링 결과, RDS의 CPU 사용률이 100%에 가깝게 측정된 것을 볼 수 있다.
많은 트래픽을 처리할 때 RDS의 CPU 사양이 부족하다는 것을 뜻한다. 즉, RDS가 병목지점이다.
1차 병목지점(DB) 해결 > 인덱스
DB 성능 개선의 방향성
1) 비효율적인 쿼리 개선하기 (인덱스 활용, SQL문 튜닝, 역정규화)
2) 수직적 확장
3) 읽기 전용 DB 도입(Read Replica)
4) 캐시 서버 도입
이번에는 게시판 글들이 생성일자를 기준으로 정렬된다는 것에 기반하여 생성일자에 인덱스를 생성하여 튜닝한다.
DataGrip에서 인덱스를 생성한 이후 다시 부하 테스트를 해보자
CREATE INDEX idx_created_at ON boards (created_at);
show index from boards;
대시보드를 통해 확인한 결과 최대 Throughputdl 4TPS 로 1.25배 증가한 것을 볼 수 있다.

대시보드를 통해 확인해보아도 RDS의 CPU 사용률은 개선된 모습을 보인다. 약 42.6% 정도 사용중이다.

그러나 이번에는 EC2 CPU 사용률이 심상치 않다. 약 92%가량 사용중이다. 이것을 해석해본다면 1차 병목지점이었던 DB는 해결하였으나 이제는 EC2가 새로운 병목지점으로 부상했음을 의미한다.
2차 병목지점(EC2) 해결 > 수평적 확장
EC2의 성능 개선 방향
- 비효율적인 로직 개선
- 정적파일 서버(S3, CloudFront) 분리
- 로드밸런서를 활용해 수평적 확장
- 수직적 확장
오토 스케일링을 통해 수평적 확장하기

로드 밸런서의 대상그룹에 같은 서버를 실행중인 EC2를 실행시켜 ThroughPut 성능을 개선할 수 있다.
1. 인스턴스 > 작업 > 이미지 및 템플릿 > 이미지 생성
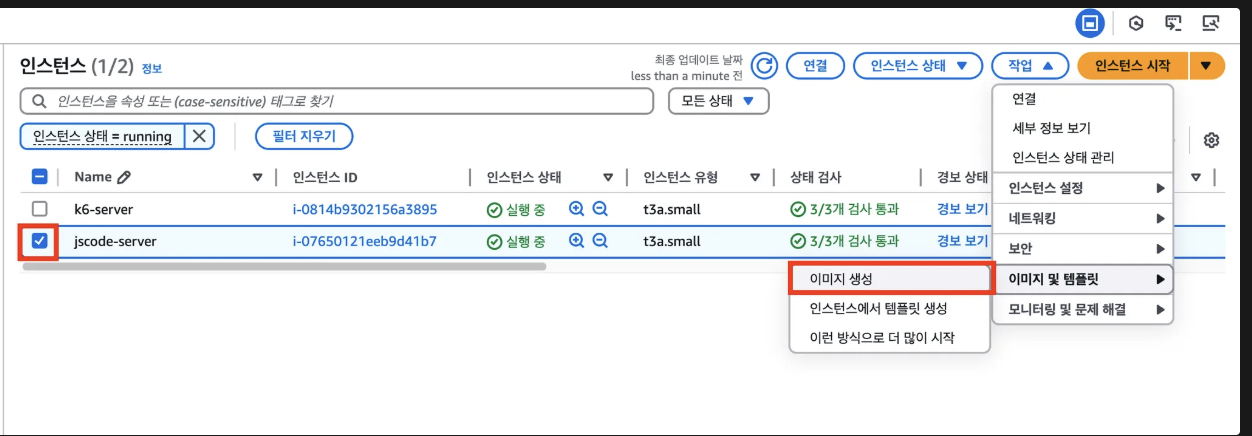
2. 이미지로 EC2 이미지 생성
이미지 > AMI > AMI로 인스턴스 시작
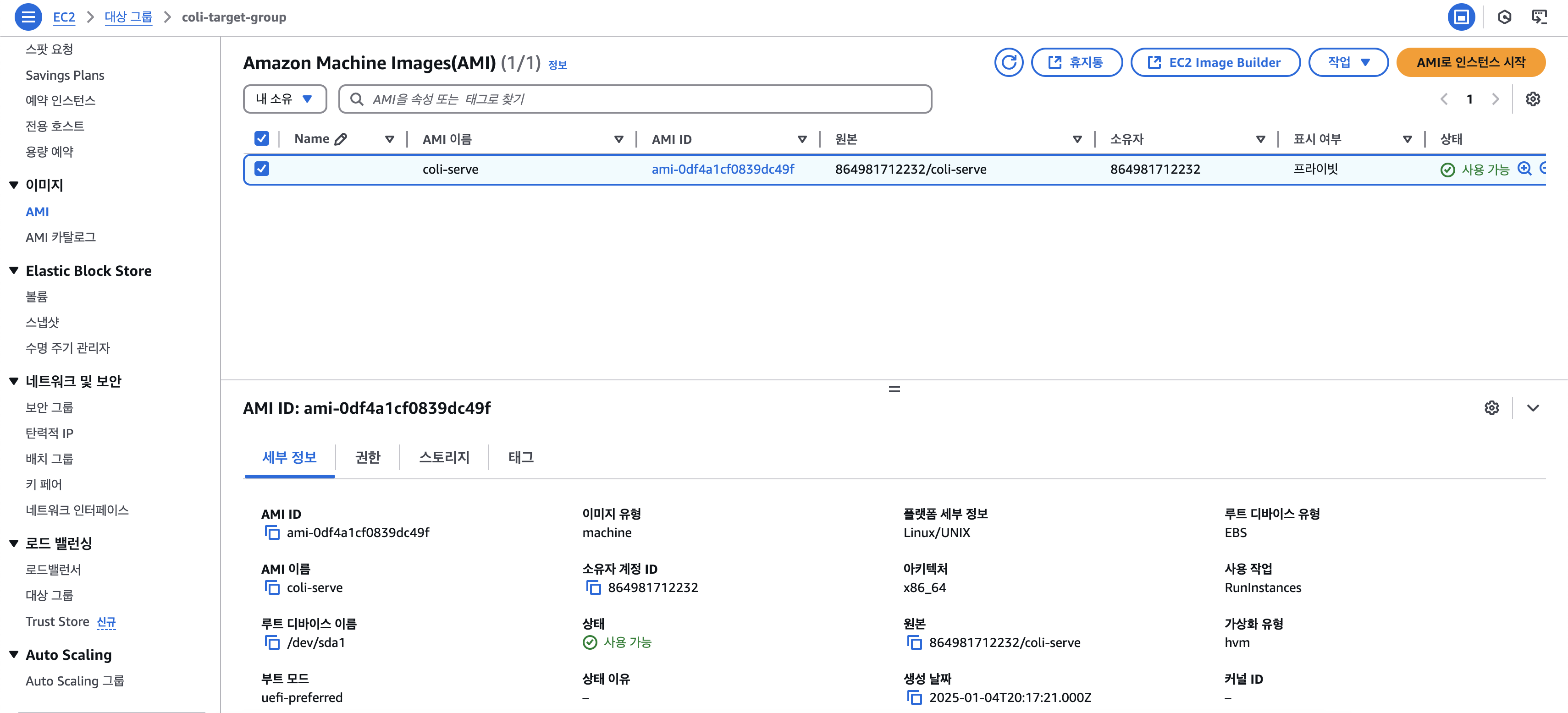
3. 동일하게 EC2에 접속하여 SpringBoot 실행시키기
$ cd /home/ubuntu
$ cd load-testing-server
$ cd build/libs
$ sudo nohup java -jar jscode-0.0.1-SNAPSHOT.jar &
4. CloudWatch Agent 실행시키기
# CloudWatch Agent 실행
$ sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -s -c file:/opt/aws/amazon-cloudwatch-agent/bin/config.json
# 잘 실행되고 있는 지 확인
$ sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -m ec2 -a status
5. Iam Role 연결
작업> 보안 > I AM 역할 수정 > 기존에 선택했던 보안그룹으로 설정
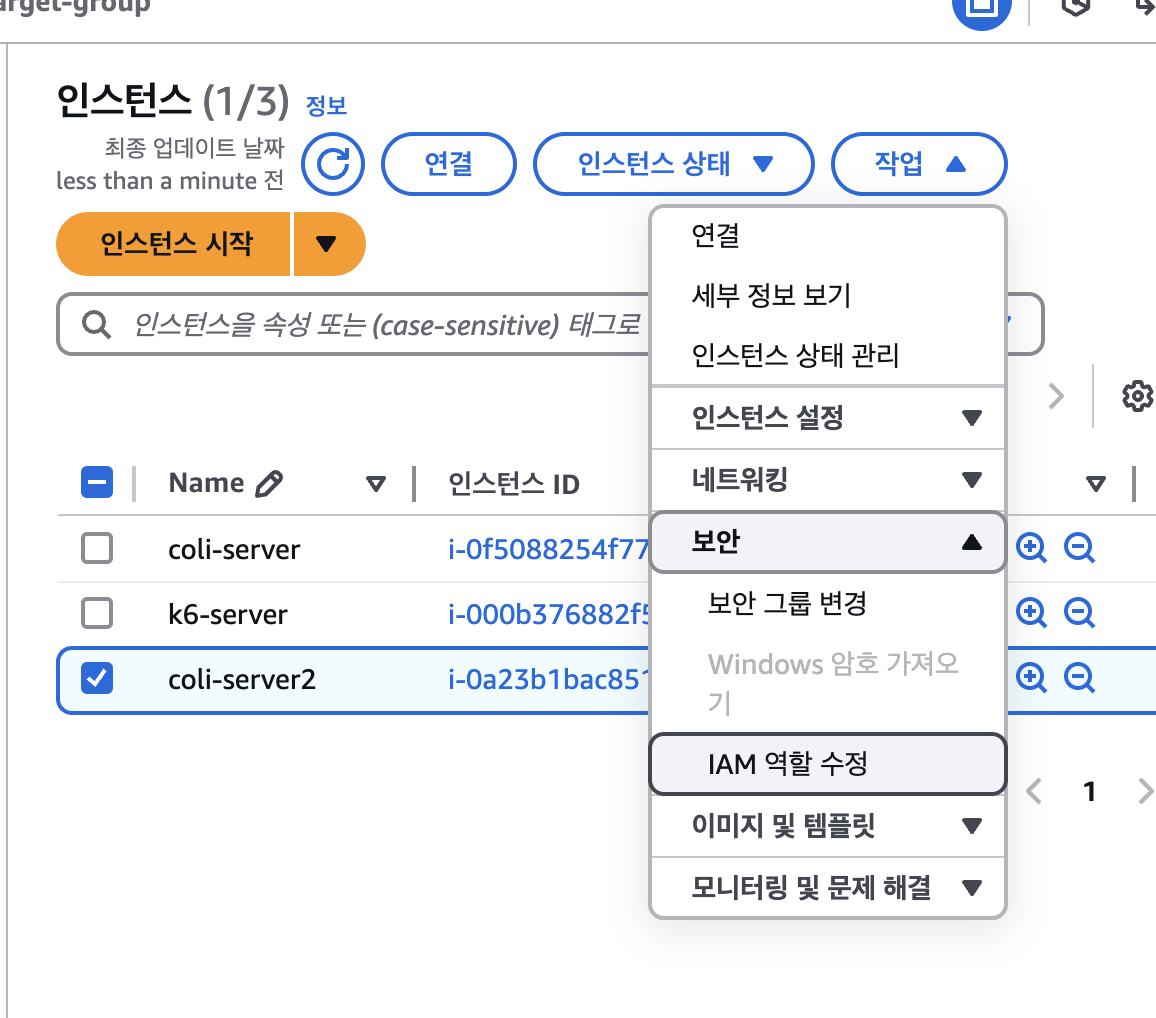
6. ALB 대상그룹에 추가하기

2차 병목 해결 후, 부하테스트 다시 진행하기
이제 다시 부하테스트를 진행해보자
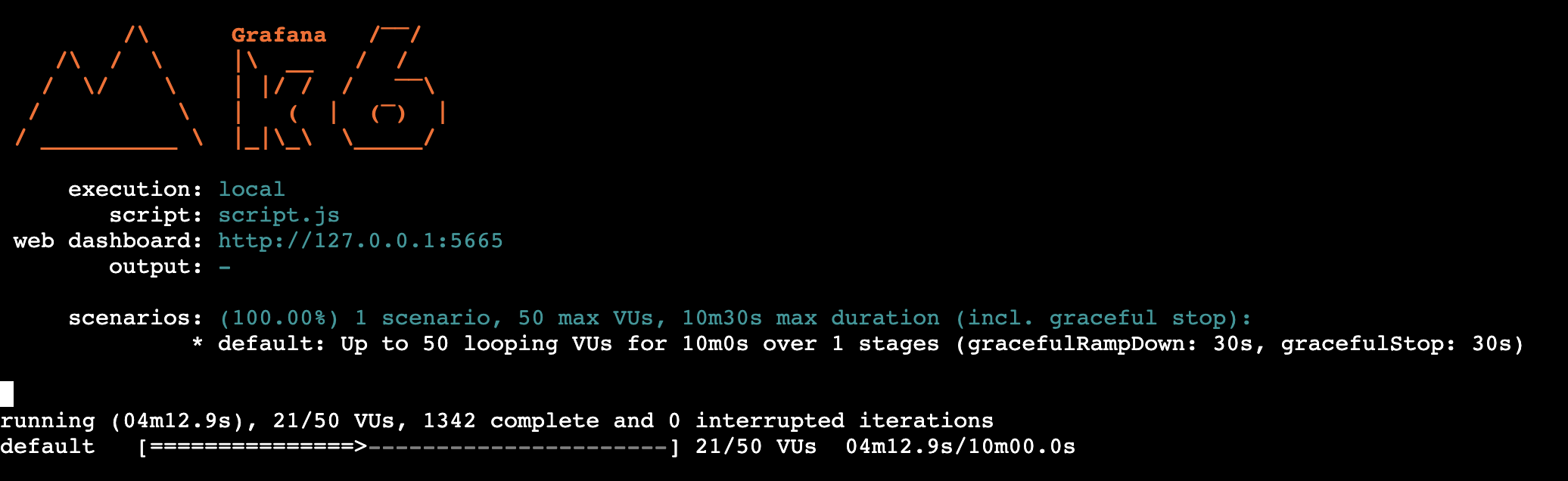
K6 대시보드를 보면 ThroughPut이 목표로 했던 TPS 8을 달성한 모습을 볼 수 있다.

그러나, 아직 RDS CPU 사용률에 비해 EC2의 CPU 사용률이 빠르게 올라가는 것으로 보아 아직까지도 EC2에서 병목 현상이 있음을 대시보드를 통해 확인할 수 있다.
