>> 문제
Samantha interviews many candidates from different colleges using coding challenges and contests.
Write a query to print the
contest_id
hacker_id
name
the sums of total_submissions
total_accepted_submissions
total_views
total_unique_views
for each contest sorted by contest_id.
Exclude the contest from the result if all four sums are 0.
Note: A specific contest can be used to screen candidates at more than one college,
but each college only holds screening 1 contest.
>> input format
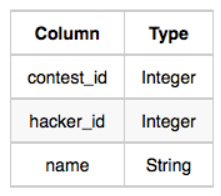
1. Contests
: contest를 개최한 해커id와 이름이 담김
2. Colleges
: 대학 id와 대학이 참여한 contest의 id가 담김

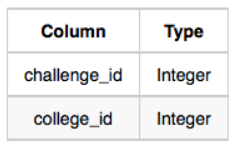
3. Challenges
: 각 문제 id와 어떤 대학에게 이 문제가 주어졌는지 대학 id가 담김
4. View_Stats
: 문제의 조회수와 고유 방문수가 담김

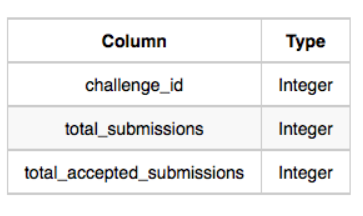
5. Submission_Stats
: 각 문제id별로 제출수와 통과 수가 담김
Sample_Input
 |
 |
 |
| Contests | Colleges | Challenges |
 |
 |
| View_Stats | Submission_Stats |

>> Out put 설명
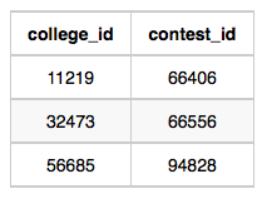
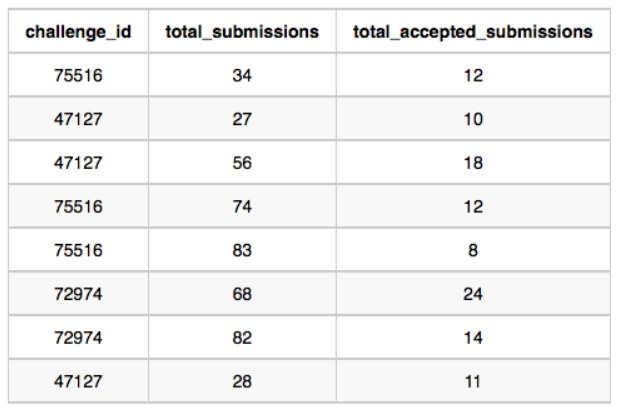
contest_id가 66406인 대회에 참여하는 대학_id은 11219이다.
11219대학에 출제된 문제는 18765와 47127이다.
각 제출 수 통계는 다음과 같다.

>>문제 설계
1단계 : View_Stats과 Submissions_Stats 를 challenge_id를 기준으로 그룹화한 테이블 만들기
2단계 : 1단계에서 만든 합산 테이블을 challenge_id를 키로 challenges_Table과 결합
3단계 : 2단계에서 만든 합산 테이블을 college_id를 기준으로 group화
4단계 : 3단계에서 만든 테이블을 colleges 테이블과 college_id를 기준으로 결합
5단계 : 4단계에서 만든 테이블을 contest_id를 기준으로 contest테이블과 결합
6단계 : 정렬 및 세부조건 맞춰주기
1단계 :
View_Stats과 Submissions_Stats 를 그룹화
결과 예시를 보면 각 대학별 id별로 문제의 조회수와 제출수를 합산해야 한다.
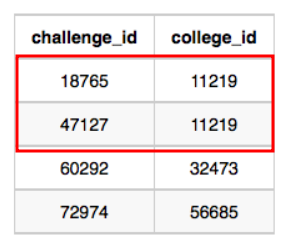
예를 들어 college_id 11219의 조회수/제출수 합산을 위해서는 문제18765와 47127을 합산해야 한다.
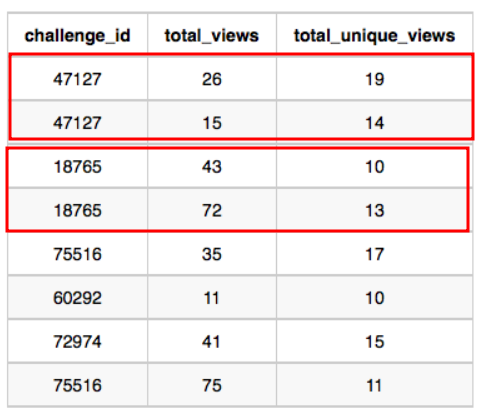 |
 |
total_view 값은 문제 47127(26+15) + 문제18765(43+72)
unique_view값은 문제 47127 (19+14)와 문제 18765(10+13)
submissions에서는 문제 47127 (27+56+28)
total_accepted_submissions에서는 문제 47127 (10+18+11)
이 답이 된다.
따라서 먼저 challenge_id를 기준으로
각각 그룹화한 view_stats과 submissions_stats 테이블을 만들어야 한다.

결과
재료1. (문제번호 - 문제별 total_view -문제별 uniqe_view)
재료2. (문제번호 - 문제별 total_submission-문제별 accepted_submission)
 |
 |
| 재료 1 결과 | 재료2 결과 |
2단계 : 1단계에서 만든 합산 테이블을 challenge_id를 키로 challenges와 결합
이제 문제번호별로 각각의 숫자가 더해졌으니
이 문제들이 어떤 대학에 속해있는지를 그룹화해야 한다.
따라서 위의 두 테이블을 challenges 테이블의 challenge_id를 키로 결합해준다.

>> 결과
문제번호 - 대학id - 재료1문제번호 - total_view -unique_view- 재료2문제번호 - total_submission- total_accepted

3단계 : 2단계에서 만든 합산 테이블을 college_id를 기준으로 group화
이제 대학별로 다시 이 수치들을 합산해주어야 한다.
따라서 2단계의 table을 college_id를 기준으로 group 화 해준다.
그리고, 각 재료들을 새로운 기준인 college_id를 기준으로 합산해주면
대학_id를 기준으로 통계값이 만들어진다.

>> 결과
(대학id - total_views - unique_views - submissions - accepted)

4단계 : 3단계에서 만든 테이블을 colleges 테이블과 college_id를 기준으로 결합
+) contest_id를 기준으로 group화

이젠 colleges 테이블에서 college_id를 기준으로 위의 테이블과 결합시켜 주면 된다.
그럼 contest_id - college_id - 통계값~~ 순으로 통계값이 나온다.

>> 결과
- 대학_id - contest_id - 우리가 구한 통계값들~~
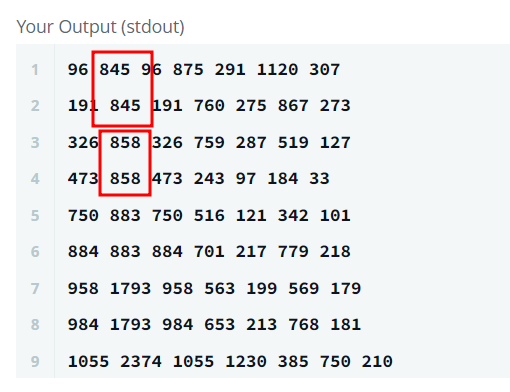
문제는 두번째 행값인 contest_id가 다른 대학에 있어 같은 값이 나온다는 것인데
이것은 한 contest에 2개 이상의 대학들이 참여하고 있음을 알 수 있다.
따라서, 다시, contest_id를 기준으로 group화하고 통계값을 합산해주어야 한다.
우리의 목적은 contest_id를 기준으로 각각의 통계값을 구하는 것이기 때문이다.

>> 결과
contest_id - 우리가 구한 통계값4개
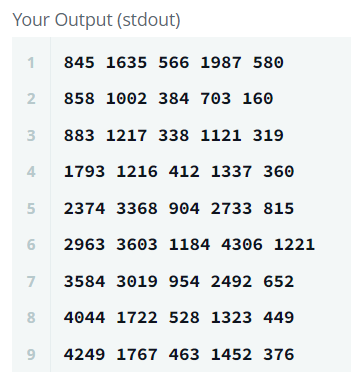
5단계 : 4단계에서 만든 테이블을 contest_id를 기준으로 contest테이블과 결합
이제 contest table과 contest_id를 키값으로 join해주면 된다.
진짜 다왔음
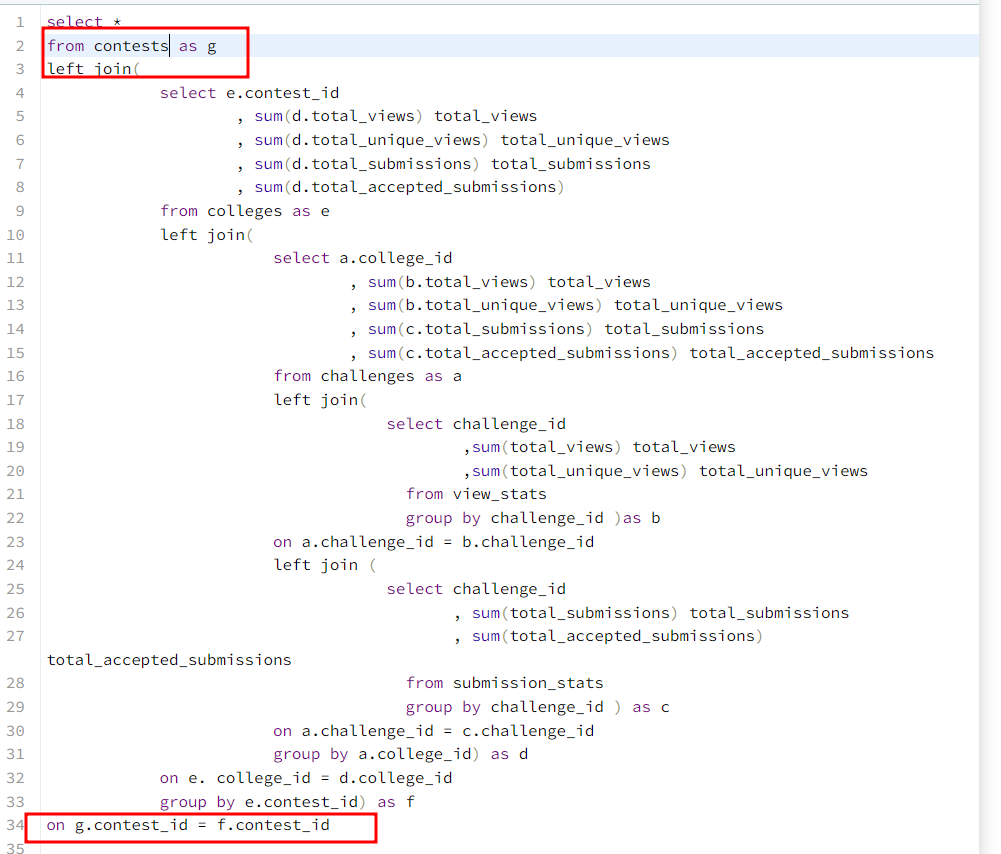
6단계 : 정렬 및 세부조건 맞춰주기
마지막으로 세부조건만 맞추어주면된다.
- contest_id를 기준으로 오름차순
- 출력 순서
- null값을 가지면 제외하기
>>최종코드
>> 결과

'데이터 분석 > SQL' 카테고리의 다른 글
| [SQLite] 폐쇄할 따릉이 정류소 찾기1 / join 키 값 불일치 설정 (0) | 2023.05.28 |
|---|---|
| [MYSQL] 550. Game Play Analysis IV / WITH절 임시 테이블 (0) | 2023.05.28 |
| [스크랩 ] MYSQL - DECODE함수 (1) | 2023.04.24 |
| [MYSQL] SQL Project Planning / 2가지 풀이 (0) | 2023.04.24 |
| [MY SQL] Symmetric Pairs / 조건분기+union (0) | 2023.04.23 |


