>>문제 상황
: 스포츠 센터의 고객 수가 늘었으나 1년간 정체 중
회원구분
- 종일회원 : 언제나 사용가능
- 주간회원 : 낮에만 사용가능
- 야간회원 : 밤에만 사용가능
- 비정기적으로 입회비 무료행사/반액할인
- 월말까지 신청하면 다음달 탈퇴가 가능
>>테이블 명세
| No. | 파일이름 | 개요 |
| 1 | use_log.csv | 센터의 이용 이력 데이터, 기간은 2018.04 -2019.03 |
| 2 | customer_master.csv | 2019.03월 말 시점의 회원 데이터 |
| 3 | class_master.csv | 회원 구분 데이터(종일, 주간, 야간) |
| 4 | campaign_master.csv | 행사 구분 데이터(입회비 유무 등) |
>>테크닉1. 데이터를 읽어 들이고 확인하자
uselog 데이터
import pandas as pd
uselog = pd.read_csv("/content/drive/MyDrive/파이썬 실무테크닉100/3장. 고객의 전체모습을 파악하는 머신러닝/use_log.csv")
print(len(uselog))
uselog.head()
customer 데이터
customer = pd.read_csv("/content/drive/MyDrive/파이썬 실무테크닉100/3장. 고객의 전체모습을 파악하는 머신러닝/customer_master (1).csv")
print(len(customer))
customer.head()
class_master
class_master = pd.read_csv("/content/drive/MyDrive/파이썬 실무테크닉100/3장. 고객의 전체모습을 파악하는 머신러닝/class_master.csv")
print(len(class_master))
class_master.head()
campaign_master
campaign_master= pd.read_csv("/content/drive/MyDrive/파이썬 실무테크닉100/3장. 고객의 전체모습을 파악하는 머신러닝/campaign_master.csv")
print(len(campaign_master))
campaign_master.head()
결론
: customer => 탈퇴유저를 포함해서 4192명
: uselog => 총 197428개로 세로로 긴 데이터
>>테크닉2. 고객 데이터를 가공하자
customer_join 생성
|
|
| customer | class mater |
|
|
| campaign_id |
=> class 기준으로 merge
=> campaign 기준으로 merge
#customer_join 생성
customer_join=pd.merge(customer, class_master, on="class", how="left")
customer_join = pd.merge(customer_join, campaign_master, on ="campaign_id", how="left")
customer_join.head()
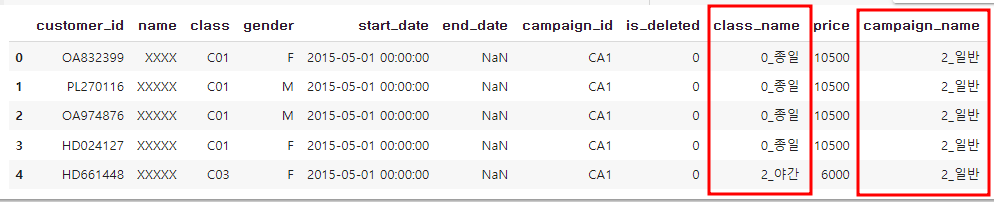
>>결측치 확인

=> end_date 결측치는 아직 회원 유지하는 이들의 데이터
=> 상대적으로 깔끔한 데이터임
테크닉3. 고객 데이터를 집계하자
집계1. : calss_name 별 회원수
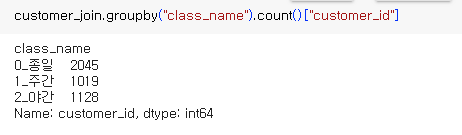
=> 종일 회원수가 많음
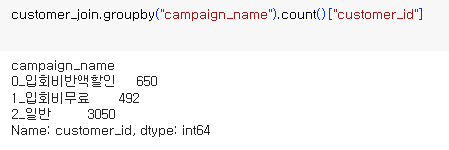
집계2. : campaign_name 별 회원수
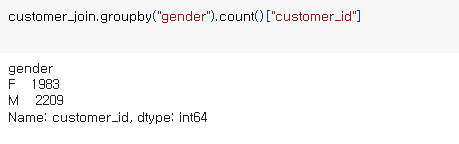
집계3. : gender 별 회원수
집계4. : is_deleted 별 회원수
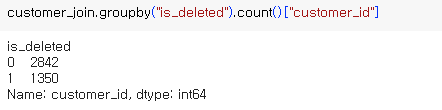
소결
+) start_date를 날짜형으로 변환
#날짜형으로 변환 후 시험삼아 기간집계해봄
customer_join["start_date"]= pd.to_datetime(customer_join["start_date"])
customer_start= customer_join.loc[customer_join["start_date"]>pd.to_datetime("20180401")]
print(len(customer_start))테크닉4. 최신 고객 데이터를 집계하자
>>최신 고객 데이터 : 2019년 3월에 탈퇴한 고객과 재적중인 고객 집계
#2019년 3월에 탈퇴한 고객과 재적중인 고객 집계
customer_join["end_date"]= pd.to_datetime(customer_join["end_date"])
customer_newer= customer_join.loc[(customer_join["end_date"]>=pd.to_datetime("20190331")) | (customer_join["end_date"].isna())]
print(len(customer_newer))
customer_newer["end_date"].unique()=> 총 2935명
집계1. : newer의 calss_name 별 회원수
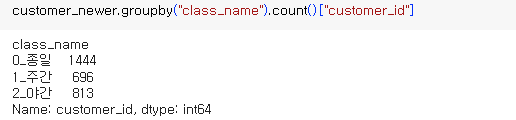
=> 종일 회원수가 많음
집계2. : newer의 campaign_name 별 회원수

집계3. : newer의 gender 별 회원수
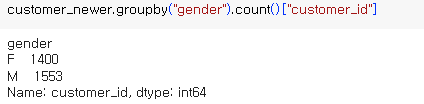
=> 소결
|
|
| 전체 customer 데이터 셋 | newer 데이터셋 |
=> 전체 중 일반 입회는 72%
=> 최신 고객 데이터(newer) 중 일반입회는 81%
=> 일반 입회 비율이 늘어남
=> 회원, 성별은 큰 변화 x
테크닉5. 이용 이력 데이터를 집계하자
>>월 이용 횟수의 평균값, 중앙값, 최댓값, 최솟값
=> 연월 - 고객 별 이용횟수 테이블
# 평균, 중앙, 최대값, 정기적 이용여부를 플래그로 작성
# 연월과 고객 id 별로 사용빈도 카운트
uselog["usedate"] =pd.to_datetime(uselog["usedate"])
uselog["연월"]= uselog["usedate"].dt.strftime("%Y%m")
uselog_months=uselog.groupby(["연월", "customer_id"], as_index=False).count()
uselog_months.rename(columns={"log_id" :"count"}, inplace=True)
del uselog_months["usedate"]
uselog_months.head()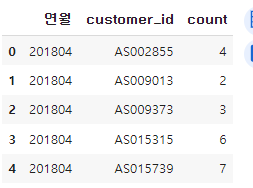
=> 고객 별 연월 이용횟수의 평균, 중앙, 최대, 최소
uselog_customer = uselog_months.groupby("customer_id").agg(["mean", "median", "max", "min"])["count"]
uselog_customer= uselog_customer.reset_index(drop=False)
uselog_customer.head()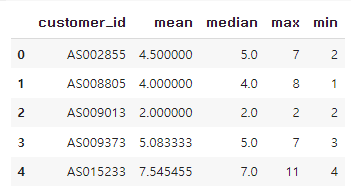
테크닉6. 정기 이용 플래그 작성
정기적이라는 것의 정의 : 이곳에서는 매주 같은 요일에 왔는지를 기준으로
# weekday : 0-6 => 월~일
=> customer_id, 연월, 요일 별 이용횟수 그룹화
uselog["weekday"] = uselog["usedate"].dt.weekday
uselog_weekday = uselog.groupby(["customer_id", "연월", "weekday"], as_index=False).count()[["customer_id", "연월", "weekday", "log_id"]]
uselog_weekday.rename(columns={"log_id" : "count"}, inplace=True)
uselog_weekday.head()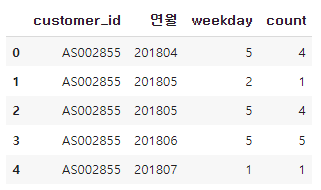
=> 같은 요일 카운트 빈도의 최대값이 4이상이면 1, 아니면 0
#numpy의 where 메소드 (https://pinkwink.kr/1236)
uselog_weekday= uselog_weekday.groupby("customer_id", as_index=False).max()[["customer_id", "count"]]
uselog_weekday["routine_flg"]=0
uselog_weekday["routine_flg"]= uselog_weekday["routine_flg"].where(uselog_weekday["count"]<4,1)
uselog_weekday.head()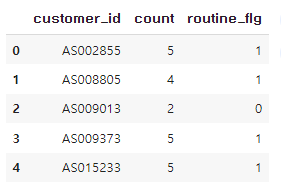
=> routine_flg가 4,5 이상인 사람은 정기적으로 방문한 고객임
테크닉7. 고객 데이터와 이용 이력 데이터를 결합
>> 현재 데이터 상황
> customer_join
>uselog_customer
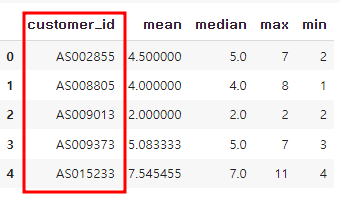
>uselog_weekday
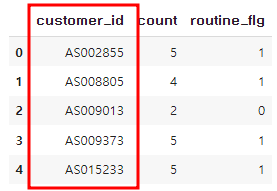
=> customer_id 기준으로 통합할 예정
customer_join= pd.merge(customer_join, uselog_customer, on="customer_id",how="left")
customer_join= pd.merge(customer_join ,uselog_weekday[["customer_id", "routine_flg"]], on="customer_id", how="left")
customer_join.head()
테크닉8. 회원 기간을 계산하자
> 회원 기간 : end_date- start_date
> 탈퇴하지 않은 인원 : 20190430로 end_date를 채움
from dateutil.relativedelta import relativedelta
customer_join["calc_date"]=customer_join["end_date"]
customer_join["calc_date"]= customer_join["calc_date"].fillna(pd.to_datetime("20190430"))
customer_join["membership_period"]=0
#시간 차이 계산
for i in range(len(customer_join)):
delta = relativedelta(customer_join["calc_date"].iloc[i], customer_join["start_date"].iloc[i])
customer_join["membership_period"].iloc[i]= delta.years*12+delta.months
customer_join.head()=> membership_period에 startdate와 end_date의 간격 즉 회원 기간을 연월 기준으로 표기

테크닉9. 고객 행동의 각종 통계량을 파악
customer_join[["mean", "median", "max", "min"]].describe()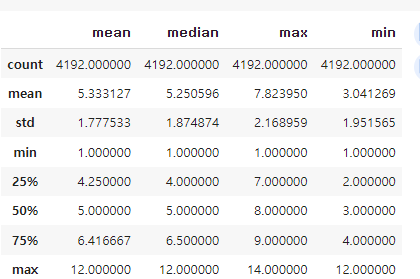
=> 여기서 mean- mean은 각 고객의 평균 이용횟수를 평균 낸 것
>> 매월 routine_flg 별 집계
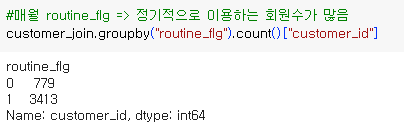
>>기간 별 count
import matplotlib.pyplot as plt
%matplotlib inline
plt.hist(customer_join["membership_period"])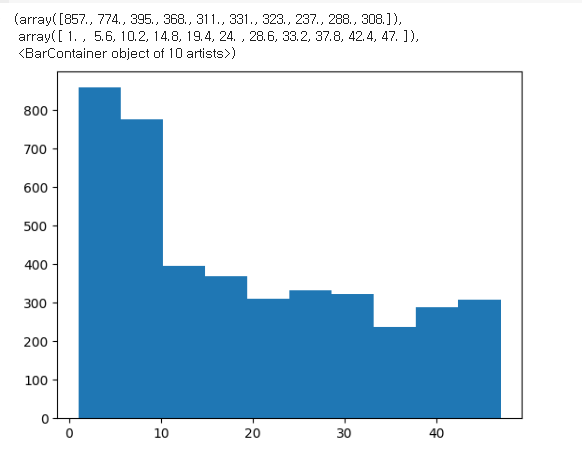
=> 소결
: 10개월 이내의 고객 수가 많고 이상은 일정함
=> 짧은 기간에 고객이 빠져나가는 업계라는 것을 시사함
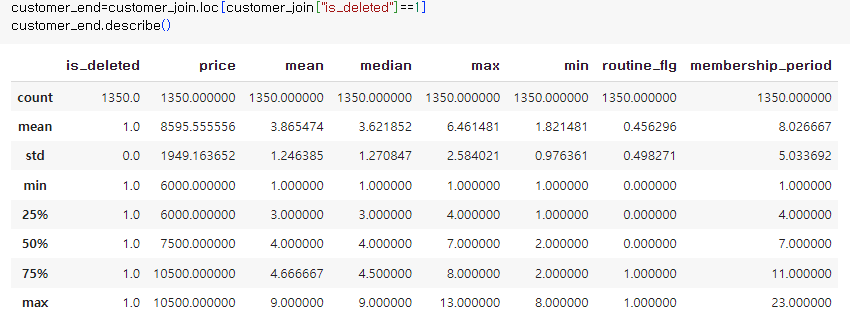
테크닉10. 탈퇴회원과 지속회원의 차이
> 탈퇴한 회원
>탈퇴 안 한 회원
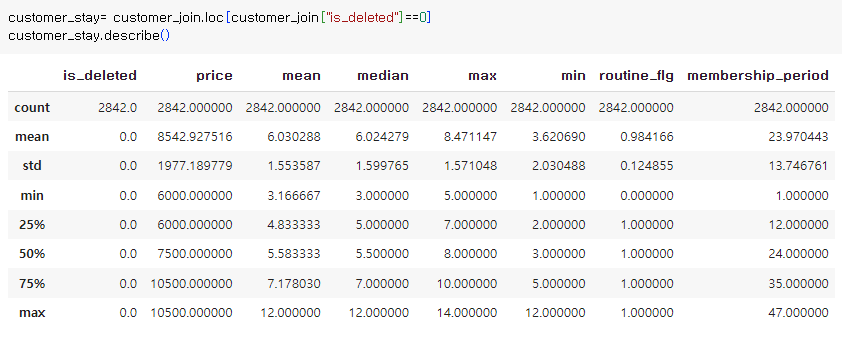
=> 매월 이용횟수
탈퇴한 회원 : 3.86
유지하는 회원 : 6.03
=> routine_flg
탈퇴한 회원 : 0.45
유지하는 회원 : 0.98
탈퇴하는 회원들은 기본적으로 운동을 안함
=> 그리고 정기적으로도 안함
=> 그래서 탈퇴함
'데이터 분석 > 파이썬' 카테고리의 다른 글
| [Python] 7570. 줄세우기(골3) / 그리디 (0) | 2024.02.06 |
|---|---|
| [나도코딩] 데이터 분석 및 시각화 - matplotlib 요약 (0) | 2023.04.12 |
| [나도코딩] 데이터 분석 및 시각화 - Pandas 요약 (0) | 2023.04.12 |
| 5-4) 범주형 변수 분석 (0) | 2023.03.29 |
| 5-3) 수치형 데이터 변수의 요약과 기술통계 (0) | 2023.03.29 |


