1. 서론
1-1. 문제상황 정의
1-1) 기존 검색 기능
-모든 페이지에 다음의 search box가 존재

-검색어를 타이핑하면 관련 결과가 보여짐
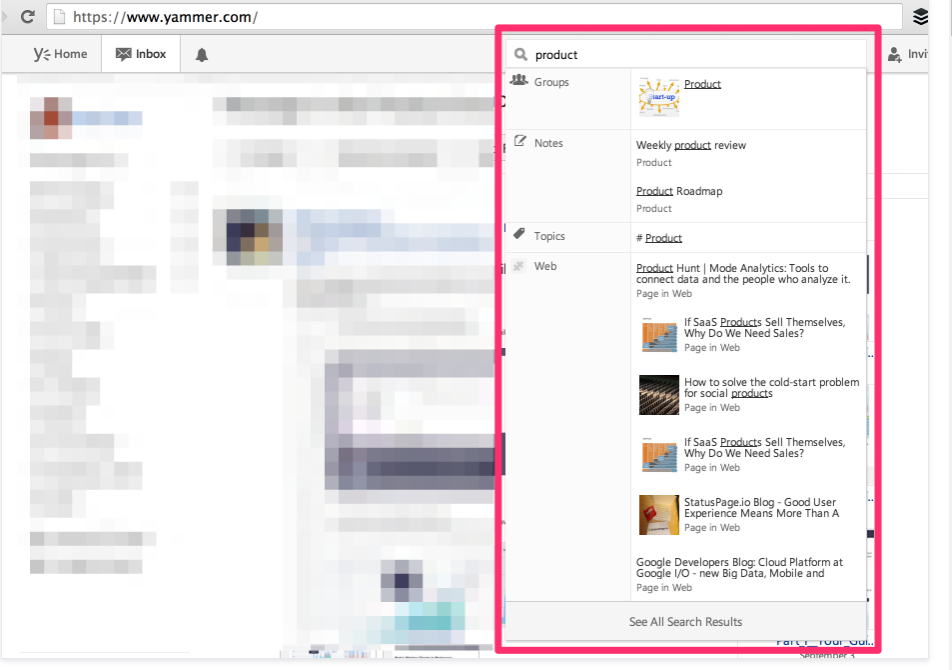
- 만약 "view all results"를 클릭한다면 -> result page로 이동
- result page 안에는 group, contersations 등 카테고리 tab별 결과 게시
- advanced search => 상세 필터를 통해 검색물 필터 기능 제공
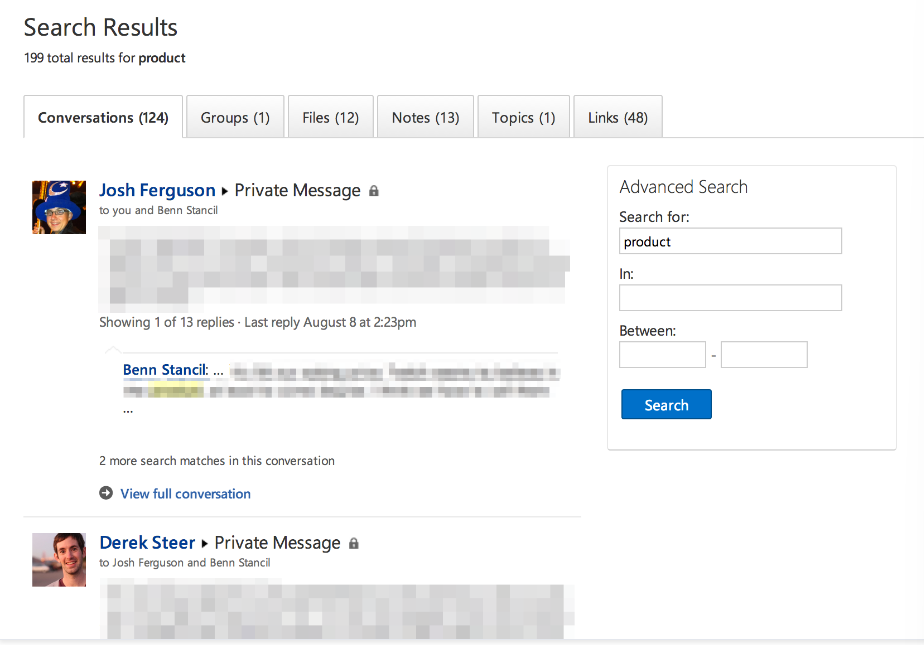
문제
- 1. search 기능을 더 추가로 개발해야하는지에 대한 여부
- 2. 어떤 식으로 기존 기능을 수정해야 가장 효율적인지
=> 어떠한 방법을 통해 정량적으로 기존 검색기능의 만족도를 평가하고 개선점을 파악할 수 있는가?
1-2. 테이블 명세서 둘러보기
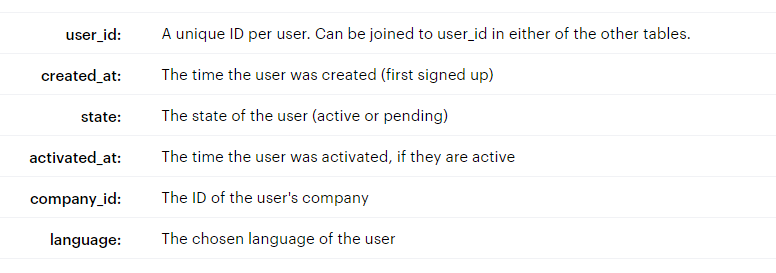
테이블1. users 테이블(tutorial.yammer_users)
- 유저 개인 정보
테이블2. events 테이블(tutorial.yammer_events)
- 이벤트 테이블(login, search 등등)
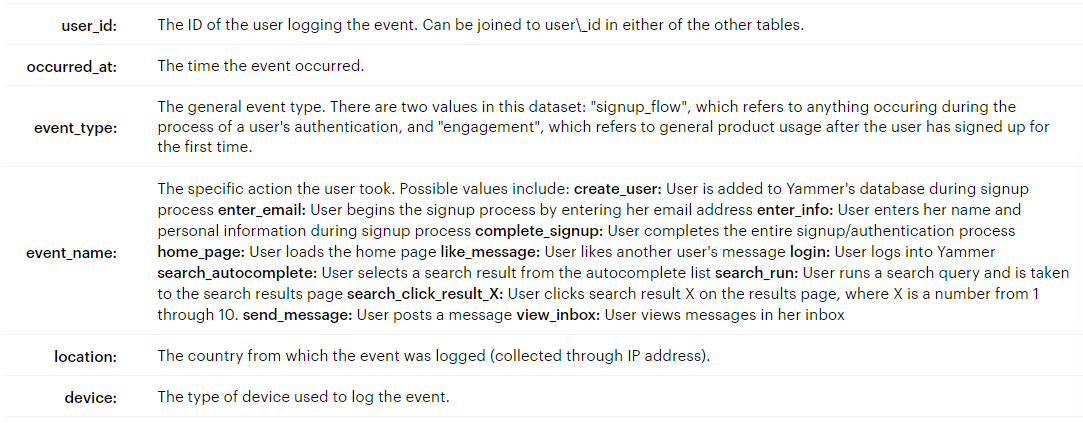
- event_name 중 search 관련 내용 설명
search_autocomplete : 검색 시 자동완성 리스트 중 선택 시
search_run : enter를 클릭 or dropdown클릭 => result page로 랜딩 시
search_click_result_X : 검색 결과 중 X번째 결과물을 선택 (1<= X <=10)
1-3. 가설 세우기
1) Search_use : 검색기능을 사용하는 비율 -> 검색기능 개선의 임팩트 파악 가능
2) Search_frequency : 검색을 사용한다면 얼마나 자주 사용하는가?/ 비슷한 검색어를 반복하지 않는가?
3) ClickThrough : 리스트에 뜬 결과물을 반복 클릭한다면 => 좋은 검색 결과가 아닐 가능성이 높음
4) Autocomplete ClickThrough : 자동검색 리스트를 클릭할 때를 따로 떼어서 바라볼 필요
2. 본론
2-1. 검색 기능 사용
2-1-1. 세션에 대한 정의
- session : string of events logged by a user without a 10-minute break between any two events.
=> 두 이벤트 간 간격이 10분 이내일때 세션이 유지됨
=> 이벤트가 발생하고 다음 이벤트까지 10분간 간격이 있다면 다음 세션으로 정의됨.
ex1) 인스타를 사용하고 20분 쉬었다가 다시 접속 => 다른 세션으로 정의
ex2) 인스타를 사용하고 8분 쉬었다가 다시 접속 => 같은 세션으로 정의
search에 대한 구분
full search : enter나 아래 see all result 버튼을 눌러 result page로 가는 경우autocomplete search : 자동완성 리스트 중 하나를 선택하는 경우
전체 세션 중 검색기능 사용의 비율
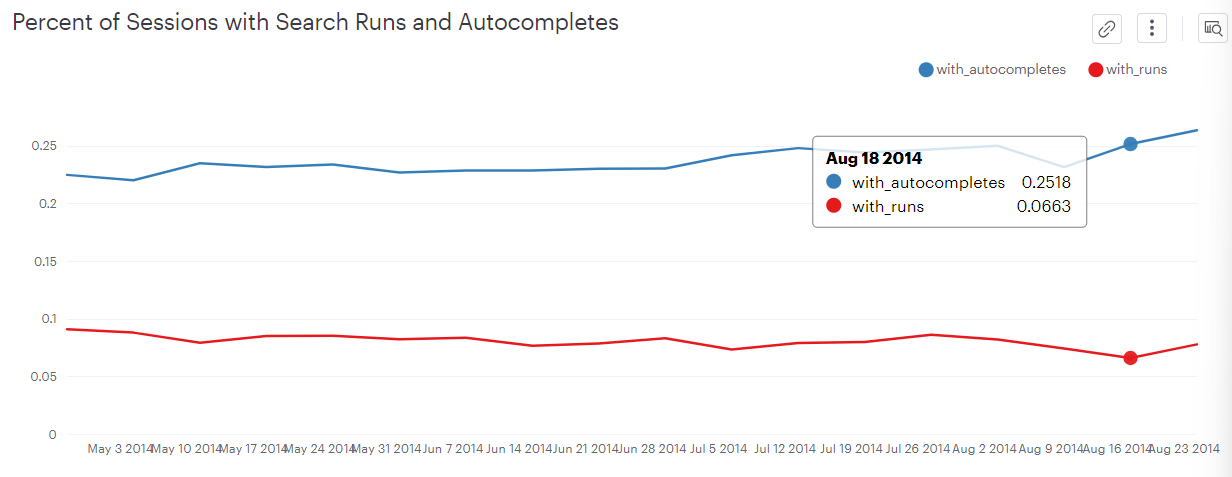
- 자동검색 사용비율이 result page 검색보다 더 많음
- 전체 세션 중 자동검색 기능 사용 비율은 약 25%
- 전체 세션 중 full search 기능 사용 비율은 약 8%
소결1.
- 검색기능을 사용하는 유저는 상당량 존재 => 검색기능 개선의 임팩트가 있음
2-2. 세션 당 검색 기능 사용 분포
2-2-1. 자동완성을 사용한 단일 세션 중 기능 사용빈도
 |
 |
-자동검색 사용 세션 중 1번만 사용한 비율이 58.6%
2-2-2. full search를 사용한 단일 세션 중 기능 사용빈도
 |
 |
- full search 기능을 한번만 사용하고 세션을 종료한 경우는 11.4%
- 그러나, full search는 특성상 유저가 더 복잡한 결과물을 얻을 가능성이 높음
=> 단순히 검색 빈도를 가지고 full search의 검색 질이 떨어진다는 결론을 내리는 것은 성급함
소결2.
- 자동검색보다 full search 사용 유저의 반복 검색 비율이 높음
2-3. 검색 결과 클릭
2-3-1. full search를 한 사용자들이 검색 결과를 클릭하는가?
=> full search 중 결과물 클릭빈도
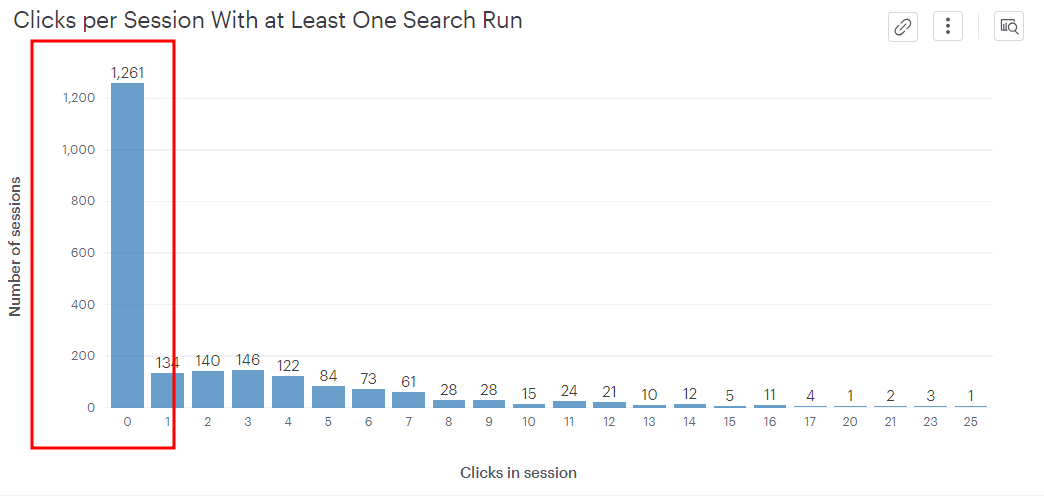
-full search의 경우 검색 결과를 한번도 클릭하지 않은 세션이 54.29%
=>의문점 : 검색 결과를 한번도 클릭하지 않은 세션이 54.29%인것이 많은 수치인가?
=> 대조군 필요
2-3-2. 세션내 검색이 많으면 검색 결과 클릭도 많이 하나?
=>full search 사용 빈도별 평균 클릭 비율
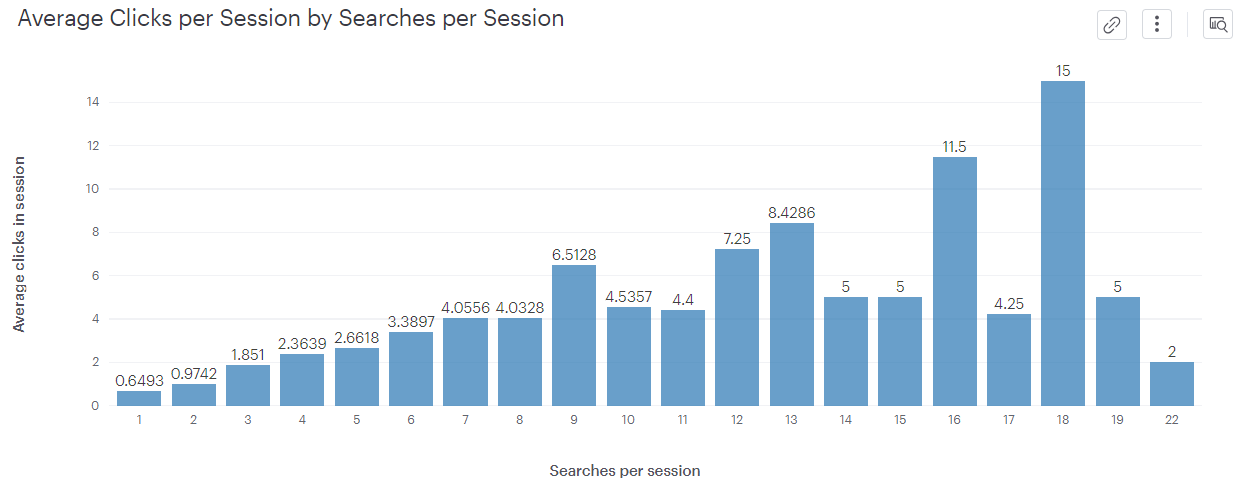
해석법
1-0.6493 : 검색을 1회한 사용자들은 평균 0.6493개의 결과물 클릭
2-0.9742 : 검색을 2회한 사용자들은 평균 0.9742개의 결과물 클릭
3-1.851 : 검색을 3회한 사용자들은 평균 1.8510개의 결과물 클릭
=> but, 검색 빈도가 높아질 수록 그 표본도 적음
=> 평균값이 전체적인 추세를 나타낸다고 보기 힘듦
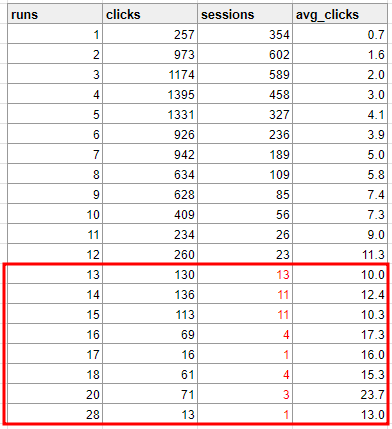
=> 17/18/20회의 경우 1,4,3 case 만 존재하므로 일반성이 성립x
소결3.
=> full search를 하고 아무것도 클릭하지 않는 비율이 54%에 달함
2-4. 검색 결과의 순서
2-4-1. full search 이후 검색 결과 페이지에서 몇번째 컨텐츠를 클릭하는가?
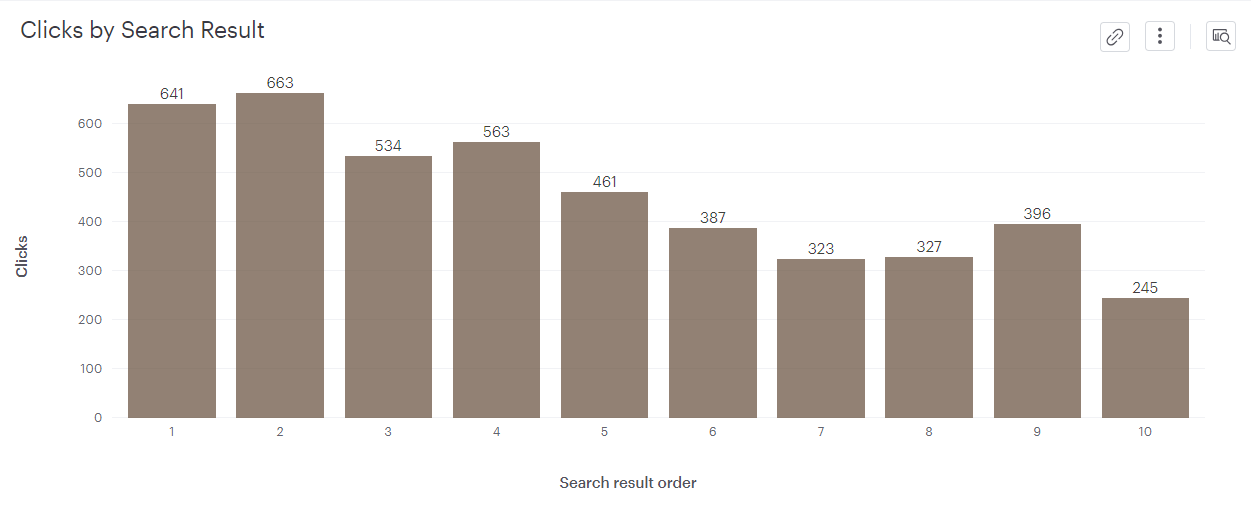
=> x축 : 검색결과 순서 / y축 : 세션 수
=> full search 이후 검색 결과 페이지에서 클릭하는 검색결과 순서는 고른편임
=> but, 앞선 분석 결과 1개의 결과만 클릭하는 비율은 2.45%
=> 결과물을 클릭하는 대부분이 웬만한 결과물을 2번 이상 클릭
=> 컨텐츠를 보여주는 순서보다 검색으로 인해 원하는 결과물을 얻지 못하는 문제가 더 큼
소결4.
-검색 결과 순서에 무관하게 사람들이 검색 결과물을 고르게 클릭
#의문점 => 나의 블로그에도 검색 상위노출이 정말 큰 영향을 주고 있을까?
실제로 네이버는 22년 9월 검색 알고리즘 변경을 두고 공정거래위원회의 시정명령에 소송을 냄
변론의 주요 내용을 요약하면
네이버 : 사람들이 상위노출된다고 클릭 안함
공정거래 위원회 : 상위노출 자체가 경쟁사보다 좋은 걸로 오인할 수 있음
출처:
https://www.edaily.co.kr/news/read?newsId=03260326632455856&mediaCodeNo=257
"네이버 검색 상위 노출됐다고 무조건 클릭 안해" vs "우량하단 오인 불러일으켜"
“이용자는 동영상을 선택할 때 상위에 노출됐다고 무조건 클릭하지 않습니다.”(네이버 측 변호사)“검색 순위 상위에 노출된다는 것은 그 상품이나 용역의 품질이 다른 경쟁 사업자보다 현저
www.edaily.co.kr
네이버는 검색어별 경쟁력 순위를 보여줌
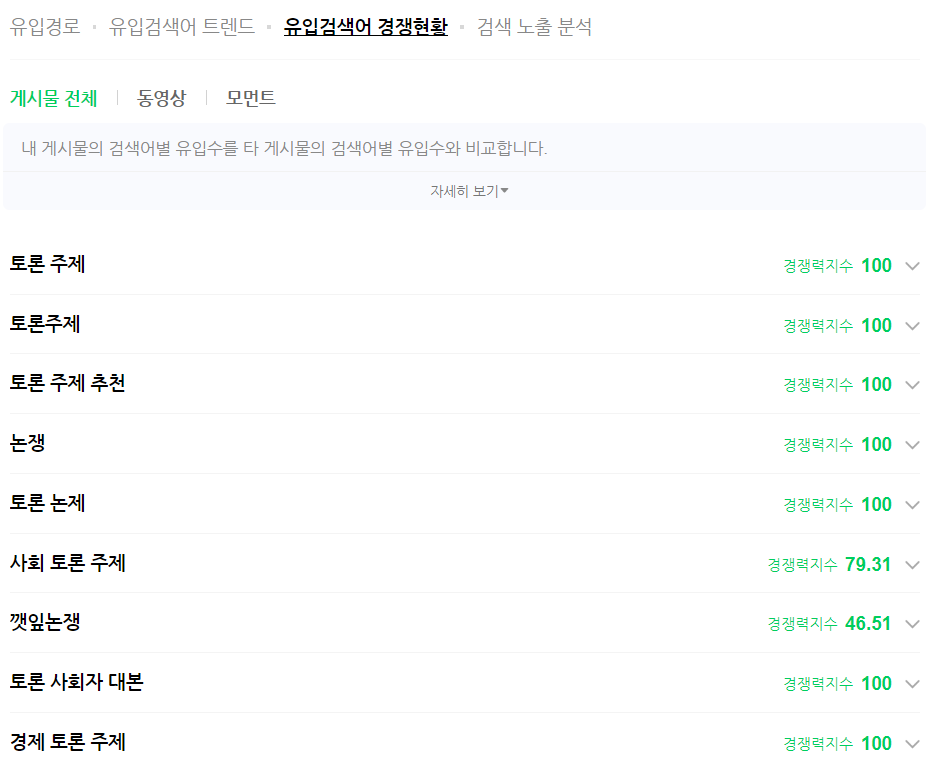
경쟁력 지수 : 가장 많은 검색 유입수를 100으로 보고 게시물의 상대지수
검색 노출 순위 평균 : 내 검색물이 노출된 순위
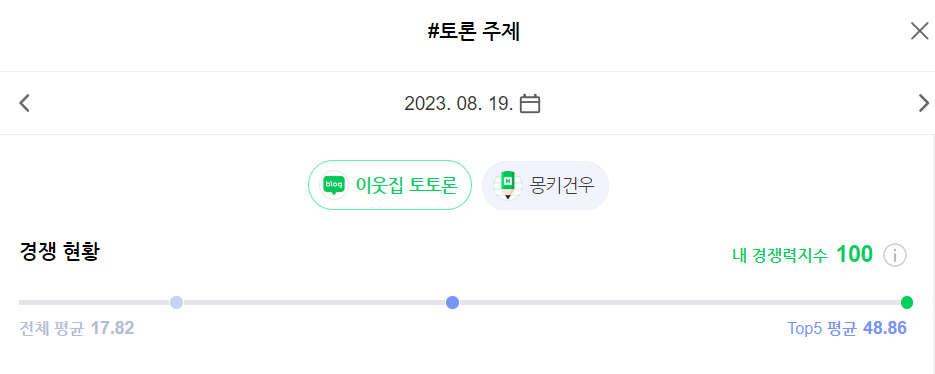
사례1) 노출 순위는 낮은데 경쟁력 지수가 1인 경우가 다수 존재
ex) #토론 주제 -> 경쟁력 지수 : 100 / 검색 노출 순위 평균 4위
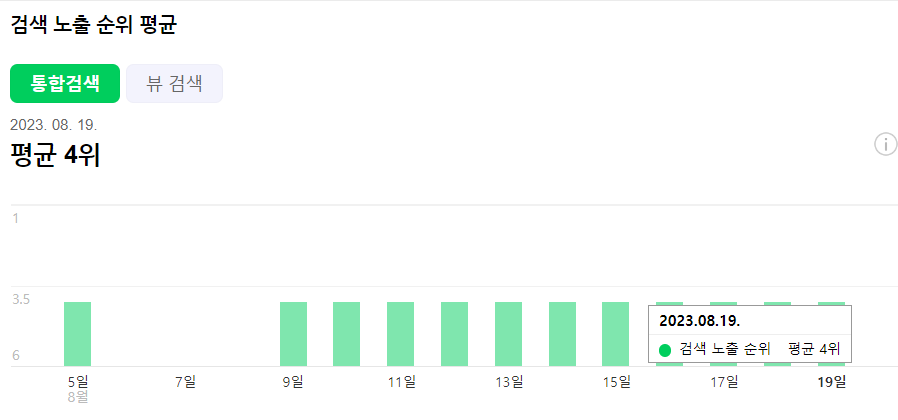
사례2) 노출은 잘되나 유입이 안되는 경우 : 검색 노출 트렌드 : 100 / 검색 유입 트렌드 : 86.67
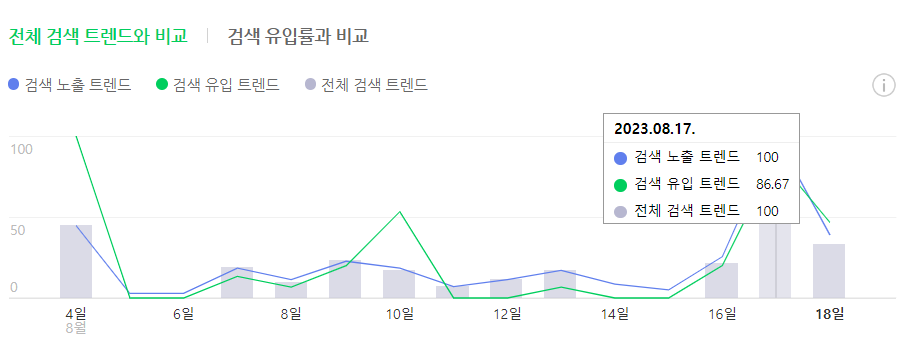
=> 상위 노출과 크게 연관은 없으나 경험적으로 view 1페이지 이내(6위 안)나 통합검색 노출은 유의하다.
2-5. 검색 재사용빈도
2-5-1. full search 또는 autocomplete를 최초경험한 사람이 한달 내 재사용하는 빈도?
case1) full search
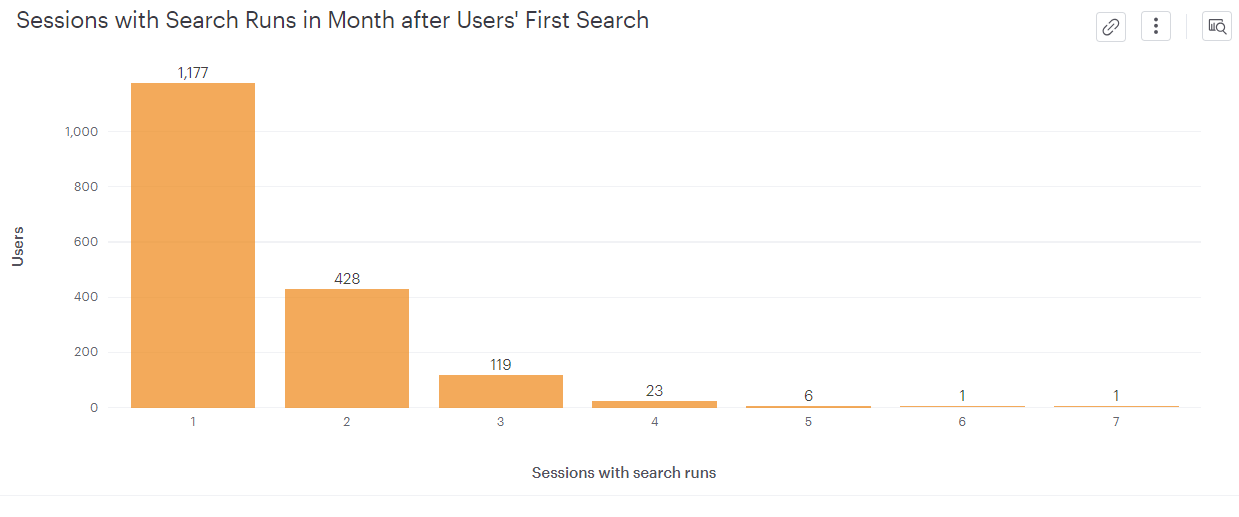
-full search최초 사용 이후 한 달 이내 재사용 유저는 1177명, 2회 사용 유저는 428명
case2) autocomplete
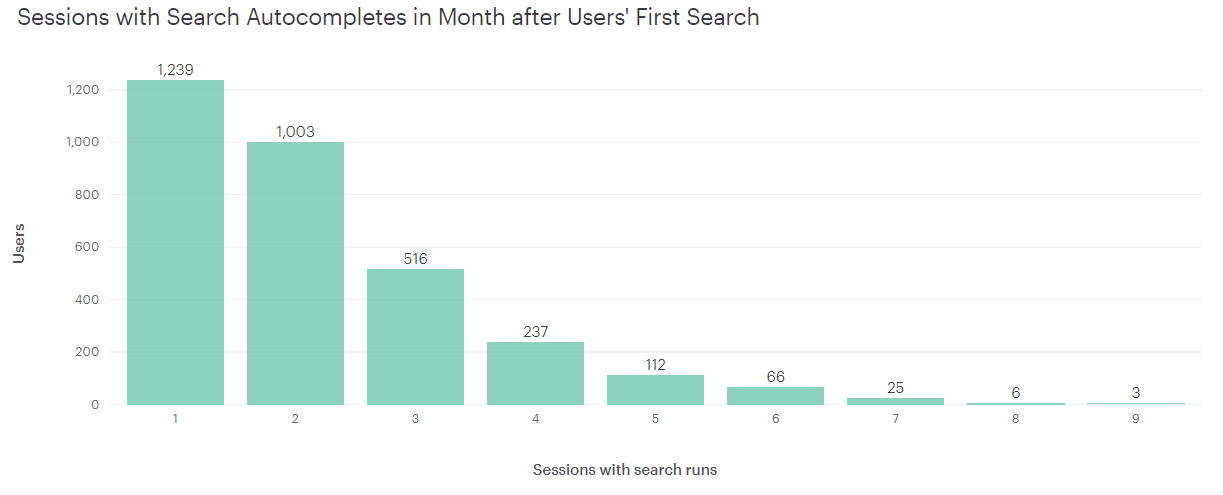
- autocomplete 최초 사용 이후 한달 내 1회 재사용 유저는 1239명, 2회 사용 유저는 1003명
소결5.
-full search의 retention 비율이 상대적으로 떨어짐
3. 결론 및 느낀점
>>소결 모음
1) 검색기능을 사용하는 유저는 상당량 존재 => 검색기능 개선의 임팩트가 있음
2) 자동검색보다 full search 사용 유저의 반복 검색 비율이 높음
3) full search를 하고 아무것도 클릭하지 않는 비율이 54%에 달함
4) 검색 결과 순서에 무관하게 사람들이 검색 결과물을 고르게 클릭
5) full search의 retention 비율이 상대적으로 떨어짐
결론
1) full search의 기능적 강점인 복잡한 수요 타겟팅 개선
복잡한 결과물을 얻고자 하는 이들이 autocomplete보다 full search를 사용한다. 그러나, full search의 사용빈도는 물론 리텐션 비율은 좋지 않은 수준을 보였다. 정교한 필터링 기능을 통해 retention을 높이기 위해서는 더 정교한 필터링이 가능하도록 개선할 필요가 있다.
2) 클릭 결과물 순위 로그의 다변화 필요성
full search 검색 결과에 대해서 결과물들의 순위를 통해 full search의 기능을 평가하고자 했으나, 실제로 유저들은 상위 노출된 결과물을 무조건적으로 클릭하지 않는다는 맹점을 가지고 있었다. 따라서 결과물들의 순위와 더불어, 몇 페이지에 있는 결과물을 클릭했는지에 대한 로그가 주어지면 좋겠다는 생각이 들었다. 단순히 1위 결과물, 2위 결과물보다 검색 1페이지의 결과물과 검색 2페이지의 결과물 클릭 기록은 검색 엔진이 얼마나 유저가 원하는 결과물을 배치했는지 알게해주는 좋은 지표가 될 수 있을 것 같았다.
3) 경우에 따른 비율과 수치 분석의 필요성
기본적으로 autocomplete과 full search은 각각 25%, 8%로 모수에 차이가 있었다. 리텐션 분석의 경우에는 수치분석보다는 각 모수별 비율 분석을 해야 상호 비교가 가능하다고 생각한다. 또한 비율 분석을 할 때는 양 비교집단의 모수가 비슷한지 그 규모를 파악하고 비율을 사용해야 기본적인 비교타당성이 성립한다는 것을 잊지말자
느낀점
1) 데이터 분석은 필름지를 선택하는 것 같다.
학창시절 과학실험 때 필름지에 따라 세상이 다른 색깔로 보이는 경험을 한 적이 있다. 솔직히 아직까지 데이터와 문제상황이 주어졌을 때 정의된 문제를 어떠한 방법으로 풀어야 할지 쉽게 떠올리지 못하겠다. 어쩌면 정해진 문제와 정해진 정답을 향한 정해진 방법들을 찾는 것에 익숙해져있어서 그런지도 모르겠다. "문제를 푼다"는 개념을 문제를 해석하고 풀어낸다는 느낌보다는 보편적인 답을 찾는다는 생각이 관성처럼 박혀있다.
조금 더 유연하게 필름지들을 나열하고 그 속에서 알맞은 필름을 찾는 연습을 하고 싶어졌다.
2) 모호함의 연속
이과적 역량을 배양해야겠다고 마음먹은 순간은 문과의 모든 것들에 모호성이 숨어있음을 체감했을 때이다. 마케팅 수업을 들을 때 좋은 결과를 받아도 결국은 교수님 취향을 저격했을 뿐 객관적으로 좋은 성과를 내었다는 느낌은 잘 받지 못했다. 모호한 느낌이 들 때마다 답답했고 결국 명확한 코드들을 추구하기 시작했다.
그러나 명확함을 찾으려하면 할수록 판단의 순간이 연속되고 그 순간들이 누적되어, 주관적인 해답을 객관적이라고 믿어버리는 꼴의 분석결과가 많이 발생했다. 결국 삶의 문제를 0과 1의 코드로 나타내는 것은 불가능하다는 결론을 요즘따라 떠올린다. 중요한 건 도출된 인사이트를 설득해낼 수 있는 힘이고 그 힘을 얻기 위해선 주장에 대한 근거가 필요하다. 데이터 분석은 그 모호하고 주관적인 주장에 설득력을 주는 도구일 뿐, 그 주장이 명확하고 절대적 진리임을 증명할 수 있는 이과적 역량은 어쩌면 실존하지 않을 수 있다.
'데이터 분석' 카테고리의 다른 글
| 비전공생 SQLD 일주일 합격 후기 feat) 요약자료 및 준비방법 (0) | 2023.12.29 |
|---|---|
| A/B test란? - 기초부터 간단한 예제까지 (0) | 2023.11.19 |
| [DB분석 실무 테크닉 100] ch2. 대리점 데이터를 가공하는 테크닉10 (0) | 2023.10.15 |


