이 글은 오디 - 폴링 로직 리팩터링 시리즈 6편의 글 중 5번째 글입니다.
[오디 -폴링 로직 리팩터링]
1. Warm up Code로 CPU 스파이크 해결하기 feat) JIT Compiler
2. 계정 로드 밸런싱으로 Request Failed를 잡아보자
3. 트랜잭션에서 외부 API를 분리하여 응답 속도를 낮춰보자
개요
프로젝트 오디의 폴링 로직에서는 10분 간격으로 외부 API를 호출합니다. 이 과정에서 호출 태스크가 queue에 머무르면서 비동기 스레드풀의 큐가 50까지 꽉 차는 경우가 발생했습니다.

이것이 문제가 되는 이유는 큐에 태스크가 대기하면서 외부 API를 호출하여 소요시간을 정확히 업데이트하는 시기가 약속 참여자별로 차이가 생기기 때문이었습니다. 특히 폴링 로직은 약속 시간 이후 1분까지만 호출하고 이후의 도착예정정보는 더이상 갱신되지 않기 때문에 약속 종료시점에 호출하는 외부 API가 1분 이상의 대기시간이 걸리면 특정 약속 참여자의 도착 예정정보가 정확하게 갱신되지 않을 위험이 있었습니다.
현재 구조를 도식화해보자

1) 100명의 도착예정정보를 10초 간격으로 동시호출함
2) Tomcat Thread Pool에서 도착예정정보를 매핑하여 반환함
3) 10분간격으로 외부 API를 호출해야 하는 상황에서 100개의 이벤트가 동시에 발행됨
4) 이벤트를 수신하여 RouteTimeCallExecutor라는 커스텀 비동기 스레드풀에서 외부 API 호출 및 소요시간 갱신이 이루어짐
비동기 스레드풀인 RouteTimeCallExecutor의 최적화 포인트는?
기본 설정은 어떨까?
@Async는 스프링 AOP를 통해 동작하는데, 이때 별다른 스레드 풀 지정이 없으면 `org.springframework.boot.autoconfigure.task;에 있는 TaskExecutionProperties의 Pool 설정이 적용되어 실행됩니다.
@ConfigurationProperties("spring.task.execution")
public class TaskExecutionProperties {
private final Pool pool = new Pool();
private final Simple simple = new Simple();
private final Shutdown shutdown = new Shutdown();
private String threadNamePrefix = "task-";
public TaskExecutionProperties() {
}
//중략
public static class Pool {
private int queueCapacity = Integer.MAX_VALUE;
private int coreSize = 8;
private int maxSize = Integer.MAX_VALUE;
private boolean allowCoreThreadTimeout = true;
private Duration keepAlive = Duration.ofSeconds(60L);
private final Shutdown shutdown = new Shutdown();
}
}
default Executor의 설정을 보면 다음과 같습니다.
corePoolSize : 8
maxPoolSize : Integer.MAX_VALUE
queue Size : Integer.MAX_VALUE
즉, 사실상 8개의 코어 스레드로 태스크를 처리하고, 큐에 무한히 대기하는 구조이며, 너무 많은 태스크가 큐에 쌓여 대기중이라면 스레드를 하나씩 늘려 무한히 생성가능합니다. 즉, 무한히 쌓아두고, 무한히 새로운 스레드를 늘리는 구조이기 때문에 OOM의 잠재적 위험이 있습니다. 따라서 애플리케이션에서 @Async를 사용한다면 인프라 환경의 가용자원을 기반으로 커스텀 스레드풀 설정이 필수적이라 할 수 있습니다.
1차 설정 : core - 4 / max - 100 / queue : 50
@Configuration
public class RouteTimeCallTaskExecutorConfig {
@Bean("routeTimeCallExecutor")
public ThreadPoolTaskExecutor spikeThreadPool(MeterRegistry meterRegistry) {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
int coreCount = Runtime.getRuntime().availableProcessors();
executor.setCorePoolSize(coreCount * 2);
executor.setMaxPoolSize(100);
executor.setQueueCapacity(50);
executor.setKeepAliveSeconds(10);
executor.setThreadNamePrefix("route-time-call-task-executor-");
executor.setRejectedExecutionHandler(new java.util.concurrent.ThreadPoolExecutor.CallerRunsPolicy());
executor.initialize();
executor.getThreadPoolExecutor().prestartAllCoreThreads();
ExecutorService executorService = executor.getThreadPoolExecutor();
ExecutorServiceMetrics.monitor(meterRegistry, executorService, "routeTimeCallExecutor", "async");
return executor;
}
}
주로 CPU 연산보다 외부 API 요청 + DB 업데이트라는 I/O 바운드 작업이 주가 되기 때문에 core 개수의 2배로 설정하였습니다. 현재 Ec2 t3g.small의 경우 2개의 코어수를 지니므로 4개의 corePoolSize로 설정되었습니다.
이 경우에 10분간격으로 100개의 동시요청 시 thread 큐에 50개의 태스크가 꽉차고 새로운 스레드가 할당되기 시작하여 pool size가 50까지 늘어났습니다.
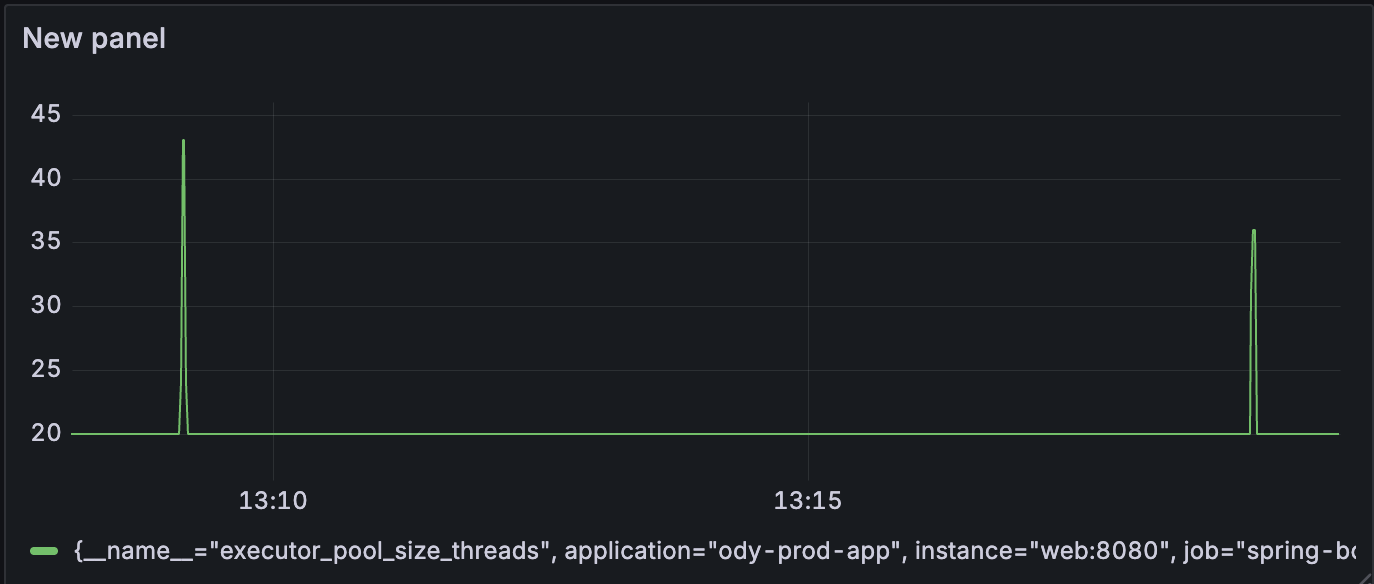
문제는 50개의 큐에 대기하는 시간이 상당히 걸렸는데 첫번째 외부 API 요청으로부터 마지막 100번째 외부 API 요청의 로그 시간 차이를 분석한 결과, 약 3-5초 정도의 딜레이가 생겼습니다.
1차 시도 - 처리시간: 3.815초
//1차 시도 - 1번째 시도
2025-09-21 14:13:39.592 [INFO] [route-time-call-task-executor-7] [] [c.o.c.c.ReplicationDataSourceRouter] - (트랜잭션 활성화 여부 : true) (readOnly : false) => WRITE DB 연결
//1차 시도 - 2번째 시도
2025-09-21 14:13:43.407 [INFO] [route-time-call-task-executor-13] [] [c.o.c.c.ReplicationDataSourceRouter] - (트랜잭션 활성화 여부 : true) (readOnly : false) => WRITE DB 연결
2차 시도- 처리시간: 5.295초
//2차 시도 - 1번째 요청
2025-09-21 17:46:04.469 [INFO] [route-time-call-task-executor-5] [] [c.o.c.c.ReplicationDataSourceRouter] - (트랜잭션 활성화 여부 : true) (readOnly : false) => WRITE DB 연결
//2차 시도 - 100번째 요청
2025-09-21 17:46:09.764 [INFO] [route-time-call-task-executor-58] [] [c.o.c.c.ReplicationDataSourceRouter] - (트랜잭션 활성화 여부 : true) (readOnly : false) => WRITE DB 연결
저는 최대한 외부 API의 호출 시점을 동시화 하여 약속참여자들이 거의 동시에 정확한 소요시간으로 업데이트 되길 원했습니다.
이에 동시요청 스파이크 요청에 최적화된 스레드풀을 커스텀하여 100개의 동시요청을 2초 내에 처리하는 것을 목표로 잡았습니다.
비동기 스레드풀 최적화로 무엇을 달성하고 싶은가?
- 최대한 동시에 업데이트가 이루어졌으면 좋겠다 : 100개 요청을 2초 이내에 모두 업데이트
- 평상시에는 최소한의 스레드를 유지하여 리소스를 절약하고 싶다
- 외부 API 동시요청 스파이크 시: 할당가능한 스레드를 확장하여 요청지연을 최소화하고 싶다
- 스레드 풀 확장 후 keepAlive Time을 최대한 짧게 잡아 빠르게 종료시키고 싶다
시도1 : corePoolSize 조정 > 큐 대기 시간은 그대로
처음에는 깊은 고민 없이 tomcat과 routeTimeCallExecutor 코어 스레드를 조정해가며 더이상 성능이 향상되지 않는 임계점을 찾고자 하였습니다.
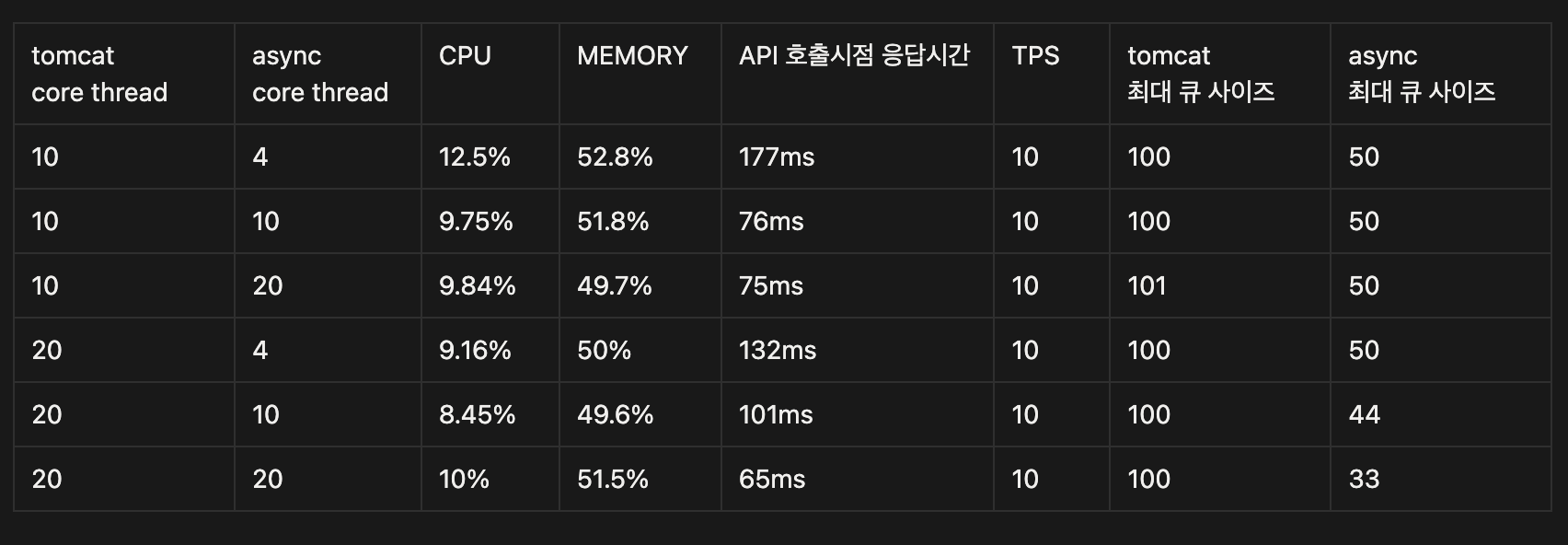
물론 core 스레드 풀 증가에 따라 처리시간이나 응답시간에 개선사안들이 보이긴 했으나, 유의미한 정도인지에 대해서는 의문이 들었습니다. 아무래도 100개 요청을 동시처리하고 50개의 큐사이즈가 고정되어 있다보니 50개의 태스크가 대기하는 과정은 비슷했고 처리시간동안 3초 내외로 유의한 차이가 나지 않았습니다.
가령 tomcat core 20 - async executor core 4를 잡아 실행한 부하테스트에서 비동기 스레드풀 사이즈는 50개는 대기하고 나머지 50개는 확장하는 모습을 보여, 최대 스레드풀 사이즈가 50까지 상승하는 모습을 보였습니다.


비슷하게 async corePoolSize를 늘리더라도 큐가 꽉 차는 현상은 지속되어 100개 동시요청의 처리시간을 유의하게 줄일 수는 없었습니다.
시도2 : maxPoolsize를 널널하게 잡고 대기 큐를 없애자
일단 tomcat 코어 스레드를 더 건드리는 것은 무의미하다고 판단했습니다. 100개 동시요청을 처리하기 위해 tomcat 스레드풀 사이즈는 결국 100으로 수렴되었습니다. 이것은 core 스레드풀을 20, 30, 40 등등 에 영향을 받지 않고 100개 가상유저 시나리오에서는 항상 100으로 스레드가 확장됨을 의미했습니다. 그렇다고 평상시 트래픽이 100명이 되지 않기 때문에 코어 스레드풀을 100이상으로 유지하여 무의미한 리소스를 낭비할 수는 없었습니다.
따라서 tomcat보다 routeTimeCallExecutor가 스파이크 요청에 최적화된 설정을 갖게하는데에 집중했습니다.
스레드풀은 코어 스레드 > 큐 > 스레드 확장 순의 과정을 거치게 됩니다. 그리고 요구사항을 톺아보면 최대한 동시 업데이트를 진행하되 평상시에는 적은 리소스를 소모하도록 하는 것이었습니다.
이에 따라 다음과 같이 스레드풀을 커스텀하였습니다.
corePoolSize : 코어 개수 X 2
maxPoolSize : 120
queue Size : 0
keepAliveTime : 3s
이렇게 하면 평상시에는 4개의 스레드풀만 대기중이다가 요청이 많아짐에 따라 큐에 대기하지 않고 최대 120개까지 스레드 확장을 시작합니다. 이는 큐에 태스크가 대기하지 않고 즉시 스레드를 만들어 업데이트 요청을 보내어 싱크를 맞추기 위한 전략이었습니다. 확장된 스레드는 3초라는 짧은 keepAliveTime 동안 호출되지 않으면 다시 빠르게 4개의 코어 스레드로 축소되어 자원을 반환합니다.
이렇게 Thread Pool을 커스텀하여 부하테스트를 진행한 결과는 다음과 같았습니다.
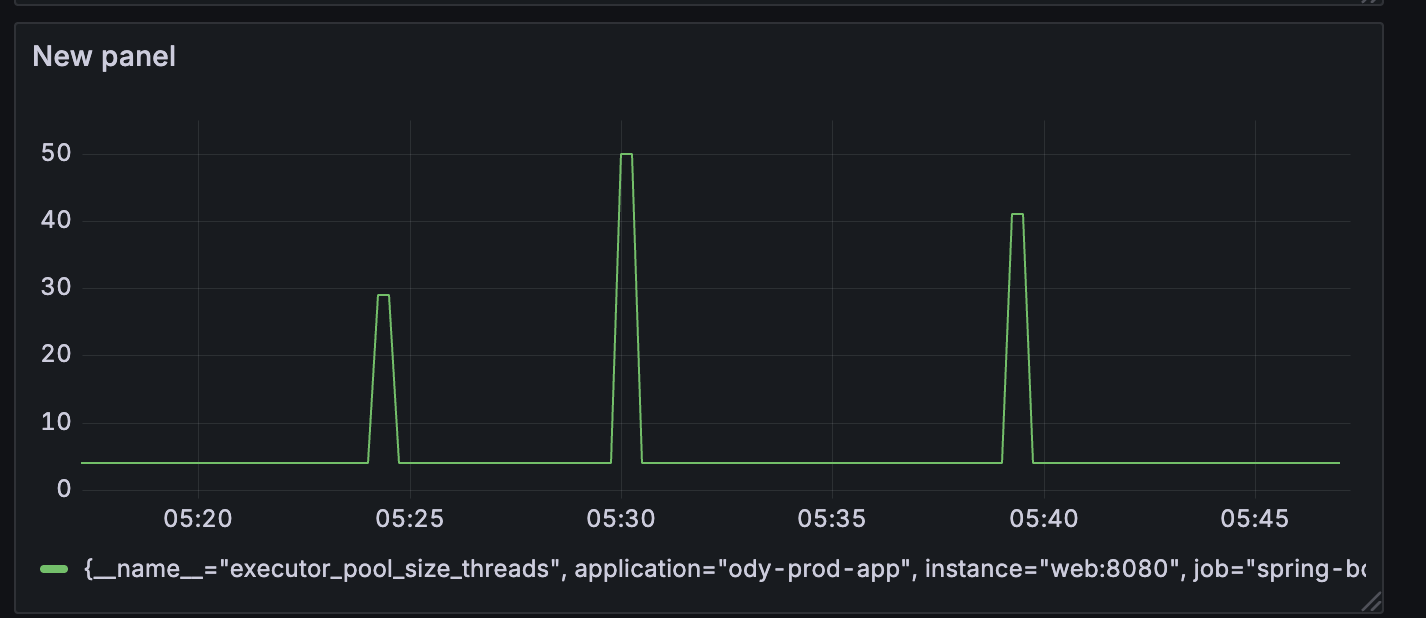
1) Async Executor의 poolSize가 빠르게 확장되어 짧은 시간 내에 동시 호출을 보장했습니다.

50개까지 천천히 pool size가 증가했던 이전 스레드풀에 비해 더 좁고 높은 형태의 스레드풀 모습이 보여졌습니다.
즉, 빠르게 스레드를 확장하고, keepAliveTime을 3초로 잡아두었기 때문에 거의 5초 이내로 PoolSize가 79에서 4까지 다시 복귀하는 모습을 볼 수 있었습니다.
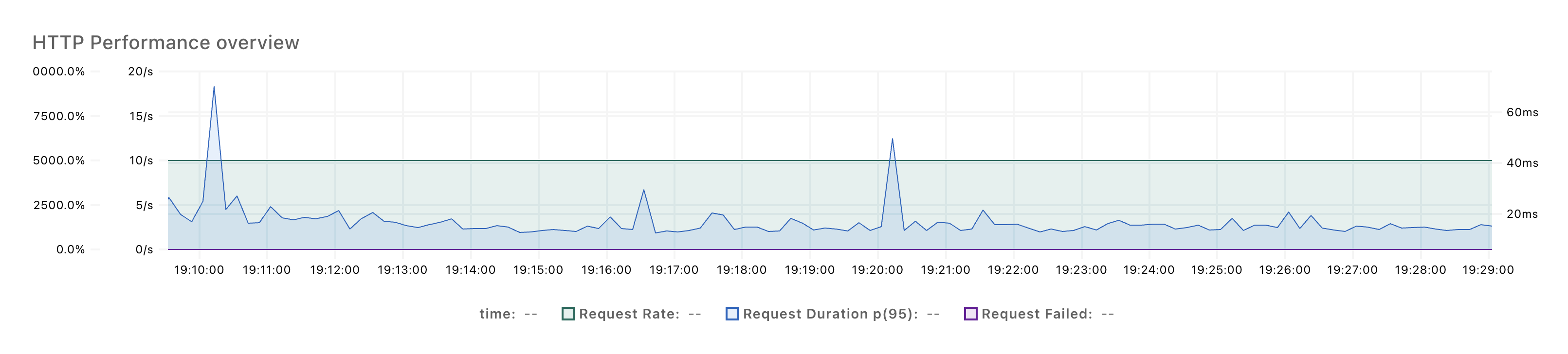
API 동시호출 100개가 진행될 동안 도착예정정보 응답시간 또한 1차 : 70ms / 2차 : 49ms로 좋은 수치를 보여주었습니다.
2) 100개 외부 API 처리시간이 2초 이내로 처리되었습니다.
//1차 처리시간 : 1.901초 (1901ms)
2025-09-21 19:10:06.352 [INFO] [route-time-call-task-executor-82] [] [c.o.c.c.ReplicationDataSourceRouter] - (트랜잭션 활성화 여부 : true) (readOnly : false) => WRITE DB 연결
2025-09-21 19:10:08.253 [INFO] [route-time-call-task-executor-118] [] [c.o.c.c.ReplicationDataSourceRouter] - (트랜잭션 활성화 여부 : true) (readOnly : false) => WRITE DB 연결
// 처리 시간 2.126초 (2126ms)
2025-09-21 19:20:07.095 [INFO] [route-time-call-task-executor-125] [] [c.o.c.c.ReplicationDataSourceRouter] - (트랜잭션 활성화 여부 : true) (readOnly : false) => WRITE DB 연결
2025-09-21 19:20:09.221 [INFO] [route-time-call-task-executor-137] [] [c.o.c.c.ReplicationDataSourceRouter] - (트랜잭션 활성화 여부 : true) (readOnly : false) => WRITE DB 연결계속해서 100개 외부 API 요청 처리시간이 3~5초 대를 찍다가 처음으로 1초대까지 내려오기 시작했습니다.
이제 queue Size 0 maxPoolSize 120을 고정하고 Async Executor의 코어 풀 사이즈를 조정하면서 100개 외부 API 요청의 평균 처리시간을 테스트해보았습니다.

| corePoolSize | 외부 API 100개 요청 평균 처리시간 |
CPU | 최대 Mem | avg pool size |
| 4 | 1.778초 | 5.65% | 52.6% | 74.5 |
| 10 | 1.654초 | 5.16% | 55.3% | 38 |
| 20 | 2.001초 | 6.35% | 50.6% | 42.5 |
그 결과 corePoolSize가 10일대 컨텍스트 스위칭을 최소화하면서도 가장 빠른 평균 처리 시간을 보였습니다. 또한 100개의 동시요청이 올 때 확장되는 pool size로 38정도로 안정적이었습니다.
최종적으로 2초 이내의 안정적인 처리를 위해 다음과 같은 최적화 옵션을 사용하였습니다.
corePoolSize : 10
maxPoolSize : 100
queue Capacity : 0
요약
- 10분간격의 외부 API 호출 시마다 풀 사이즈 확장에 따라 호출 시점에 싱크가 맞지 않는 상황 발생
- 스파이크를 잘 수용할 수 있는 비동기 스레드풀 커스텀 최적화가 필요해짐
- tomcat Thread Pool 설정은 큰 영향이 없었음
- Async Thread Pool의 core Thread는 4- 10- 20으로 실험해본 결과 10개가 가장 짧은 처리시간과 pool size peek를 보임
- corePool : 10, maxPool 10, 큐사이즈 0으로 커스텀 설정함
[오디 -폴링 로직 리팩터링]
1. Warm up Code로 CPU 스파이크 해결하기 feat) JIT Compiler
2. 계정 로드 밸런싱으로 Request Failed를 잡아보자
'프로젝트 > 오디' 카테고리의 다른 글
| [오디] '따닥' 중복 삽입 동시성 이슈 대응을 위한 8가지 대안 (5) | 2025.10.30 |
|---|---|
| [오디 - 폴링 로직 리팩터링] 5. 리팩터링 총 정리 및 느낀 점 (2) | 2025.09.22 |
| [오디 - 폴링 로직 리팩터링] 3. 트랜잭션에서 외부 API를 분리하여 응답 속도를 낮춰보자 (0) | 2025.09.21 |
| [오디 - 폴링 로직 리팩터링] 2. 계정 로드 밸런싱으로 Request Failed를 잡아보자 (0) | 2025.09.21 |
| [오디 - 폴링 로직 리팩터링] 1. Warm up Code로 CPU 스파이크 해결하기 feat) JIT Compiler (2) | 2025.09.21 |



