이 글은 총 6편의 오디 - 폴링 로직 리팩터링 시리즈 글 중 2번째 글입니다.
[오디 -폴링 로직 리팩터링]
1. Warm up Code로 CPU 스파이크 해결하기 feat) JIT Compiler
2. 계정 로드 밸런싱으로 Request Failed를 잡아보자
3. 트랜잭션에서 외부 API를 분리하여 응답 속도를 낮춰보자
개요

오디 폴링 로직 리팩터링을 위해 K6로 부하 테스트를 진행하던 중 CPU 스파이크가 튀는 문제가 발생했습니다.
본 글은 CPU 스파이크 해결을 위해 Jit Compiler Warm Up 순으로 해결방안을 시도했던 기록을 담습니다.
Jit Compiler가 코드를 최적화하는 과정을 알아보고 필요한 Warm up량을 측정하는 과정을 서술합니다.
해당 스파이크는 서버가 배포된 직후 첫번째 부하테스트를 할 때 발생하였으며, 두번째 부하테스트를 진행하면 스파이크가 발생하지 않았습니다
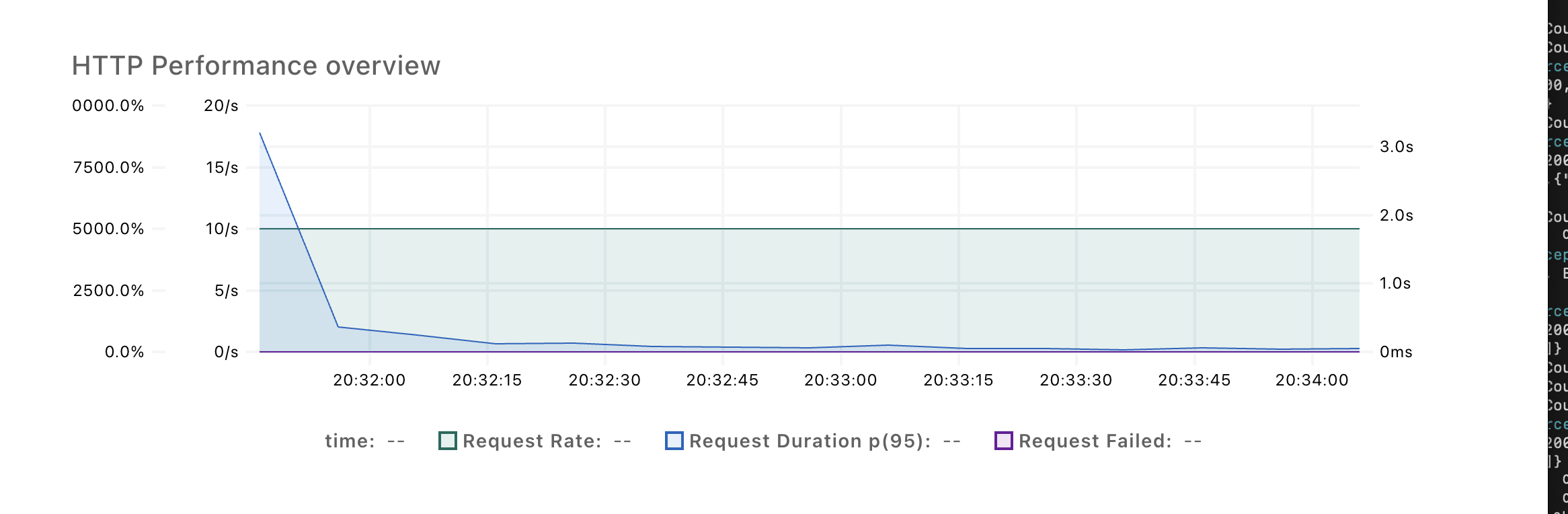 |
 |
| 첫 부하테스트 요청에는 Request Duration이 3.2s나 잡힌다 | 두번째 부하테스트부터는 593ms로 대폭 줄어든다 |
. 따라서 배포 직후 서버가 초기화되는 과정에서 JVM 로드 혹은 최적화 과정에서 필요한 리소스가 문제이지 않을까 싶었습니다.
첫번째 가설 : 새로운 스레드 생성에 필요한 자원인가?
첫번째 가설은 갑작스러운 100개 동시요청으로 인하여 스레드를 새로 할당하는 과정에서 스파이크가 발생했다는 것입니다.
현재 Tomcat Thread Pool의 디폴트 옵션을 사용하고 있기 때문에 coreThread = 25, maxThread = 200, queueSize = Integer.MAX_VALUE로 설정이 되어 있습니다.
갑작스러운 100개 요청이 오면 coreThread 25를 넘어 요청을 생성하기 위한 새로운 스레드를 생성하기 위한 비용이 들지 않을까 했습니다.
그러나, 스레드 풀에서 스레드를 할당하는 우선순위 순서는 코어 스레드 > 큐 대기 > max 스레드까지 스레드 생성입니다. 따라서 100개의 동시요청이 온다고 하더라도 이므로, 작업이 큐에 대기하지 새로운 스레드 생성을 시작하지 않기에 원인이 아니라 생각했습니다.
두번째 가설 : JVM 클래스 로드 과정에서의 문제인가?
두번째 가설은 JVM이 메모리에 클래스 파일을 로드하는 과정에서 스파이크가 발생했다는 것입니다.
JVM은 모든 클래스 파일을 메모리에 올려두지 않고 실제 호출이 되었을 때를 기점으로 파일 로드 > 링킹 > 초기화의 과정을 거칩니다.
이에 서버가 배포되고 나서 관련 객체들을 조회하여 클래스를 로드하는 Warm-up 코드를 실행해주었습니다.
@GetMapping("/warm-up")
public String warmUp() {
for (int i = 1; i < 41; i++) {
meetingRepository.findById((long) i);
}
for (int i = 1; i < 101; i++) {
mateRepository.findById((long) i);
etaRepository.findById((long) i);
}
return "warmup-done";
} |
 |
그러나 스파이크 문제는 여전했습니다.
직접 Ec2에서 확인해보자
그래서 직접 Ec2에 들어가서 무엇이 리소스를 쓰고 있는지 보기로 했습니다.
리눅스 환경에서 top -H 명령어를 치면 각 스레드별로 CPU와 메모리를 얼마나 사용중인지 보여줍니다.
처음에는 잠잠하다가 부하테스트가 시작하자마자 갑자기 C1 Compiler, C2 Compiler 스레드가 튀어나와 CPU를 30-50% 메모리를 많으면 60%까지 사용하기 시작합니다.
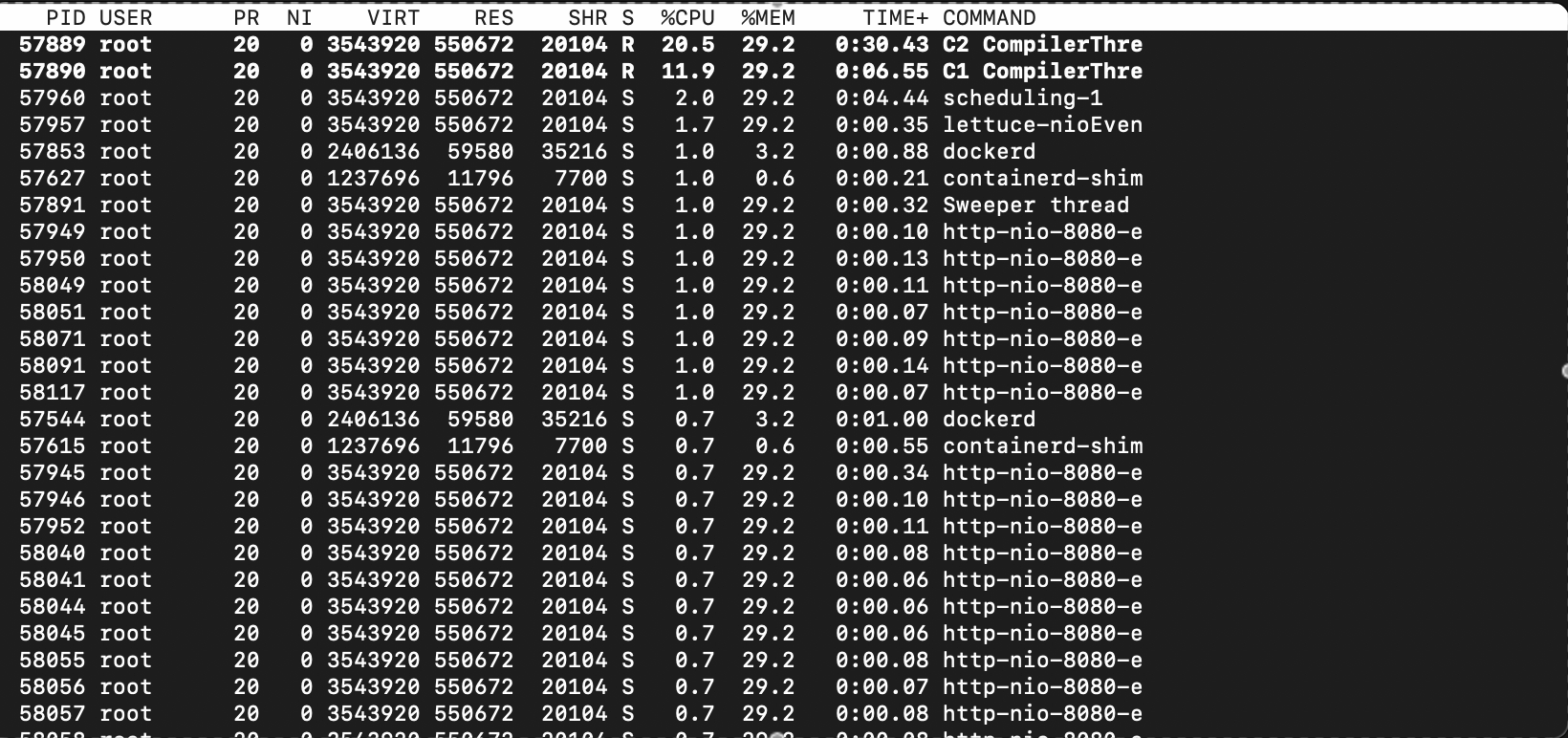
그럼 C1, C2 Compiler란 무엇일까요?
자바의 컴파일 과정
자바는 중간언어인 Byte Code로의 변환 과정을 거치기 때문에 컴파일 과정이 크게 2스텝으로 나뉘어집니다.
1) Java > Byte Code
2) Byte Code > Binary Code(기계어)
여기서 첫번째 스텝을 도식화 하면 다음과 같습니다.

Java > Byte Code
1) 개발자의 소스 코드(.java)를 자바 컴파일러가 읽는다
2) 자바 컴파일러는 소스코드를 컴파일된 바이트코드(.class)로 변환한다.
3) 클래스 로더가 클래스 로딩 및 필요한 클래스들의 링크 및 초기화를 완료한다.
4) 컴파일된 바이트코드들을 JVM 메모리에 올린다.
Byte Code > Binary Code(기계어)
이제 JVM 메모리에 올라와있는 바이코드들을 바이너리 코드(기계어)로 변역해야 실제 기계가 실행이 가능합니다.
그리고 JVM은 그 방식을 인터프리터, Jit Compiler 두 가지를 혼용하여 사용합니다.

1) 인터프리터
: 바이트 코드를 한줄씩 읽어 실행하는 것으로 최적화가 될 되어 있다.
: 속도가 느리다.
2) JIT Compiler
: 전체 바이트 코드를 한번에 컴파일 해 바이너리 코드로 변환한다.
: 다음에 같은 코드를 실행할 때는 이미 컴파일된 바이너리 코드를 활용한다.
2-1) C1 Compiler
: 최적화율을 희생하고 빠른 애플리케이션 시작을 보장하는 컴파일러
: 속도가 빠르지만 최적화 효율은 떨어진다.
2-2) C2 Compiler
: 더 많은 실행 정보를 기반으로 최적화된 바이너리 코드를 제공하는 컴파일러
: 속도가 느리지만 최적화 효율이 높다
JVM은 빠른 실행과 최적화 라는 두가지 가치의 중용을 위해,
메서드 호출량이나 메서드 정보를 런타임에 수집(Profiling)하고 이 정보를 기반으로 컴파일할 Compiler를 선택합니다.
그리고 메서드 호출이 호출량에 따라
인터프리터 > C1 Compiler > C2 Compiler 순으로 Byte Code > Binary Code의 컴파일 효율을 높혀갑니다.
그리고 Compiler 선택의 기준이 되는 각 호출량 기준에 따라 총 5가지 레벨을 구분하고 있습니다.
| 단계 수 | 선택한 컴파일러 | 설명 |
| 0단계 : Interpreted Code | Interpretor | - 인터프리터를 통해 한줄씩 바이트코드 해석, 성능이 가장 좋지 않고 시간이 오래걸림 |
| 1단계 : Simple C1 Compiled | C1 Compiler | - 정보 수집을 시작하지 않고 바이트 코드 전체를 컴파일하여 실행(JIT) - 주로 너무나 간단해서 C2 Compiler도 더이상 최적화하기 힘든 메서드들을 컴파일 |
| 2단계 : Limited C1 Compiled | C1 Compiler | - light profiling으로 최적화를 위한 가벼운 정보 수집을 바탕으로 최적화하여 컴파일 |
| 3단계 : Full C1 Compiled | C1 Compiler | - full profiling으로 최적화를 위한 정보수집을 최대한 모두 활용하여 바이트 코드를 C1 Compiler가 가능한 최대한의 최적화된 바이너리 코드로 변환 |
| 4단계 : C2 Compiled | C2 Compiler | - 그동안의 컴파일 정보로 C2 Compiler가 더 많은 시간과 메모리를 활용하여 더욱 최적화한 바이너리 코드로 변환 |
전반적으로 호출량이 많아지고 자주 사용되는 코드라고 판단이 될 수록, 최적화를 위한 정보수집(Profiling)의 강도를 높이고, 더 많은 시간과 메모리를 활용하여 최적화 및 캐싱을 활용하는 것이 전반적인 맥락입니다.
그리고 Ec2에서는 다음 명령어를 통해 JVM이 각 레벨에 다다르기 위해 어느정도의 메서드 호출량을 필요한지 알 수 있습니다.
java -XX:+PrintFlagsFinal -version | grep Threshold | grep Tier

여기서 해석가능한 각 레벨별 호출량의 기준은 다음과 같습니다.
| 레벨 | 호출량 기준 |
| 레벨2 > 레벨3 | 200 |
| 레벨3 > 레벨4 | 5000 |
Warm up을 통해 Lv4로 C2 Compiler 최적화하고 부하테스트를 진행하자
부하테스트에서 JIT Compiler 프로파일링과 최적화 과정에서 사용되는 CPU 리소스로 테스트 결과가 왜곡되는 현상을 막고자 했습니다. 이에 따라 레벨 4 최소 호출량인 5000번을 충족시켜 JVM 실행엔진이 완전히 최적화된 상황에서 테스트를 진행하고자 하였습니다.
이에 따라 약 10분간 10초 간격으로 도착 예정정보를 요청하는 Warm up 부하를 발생시킨 이후, 다시 부하테스트를 실행해보았습니다.
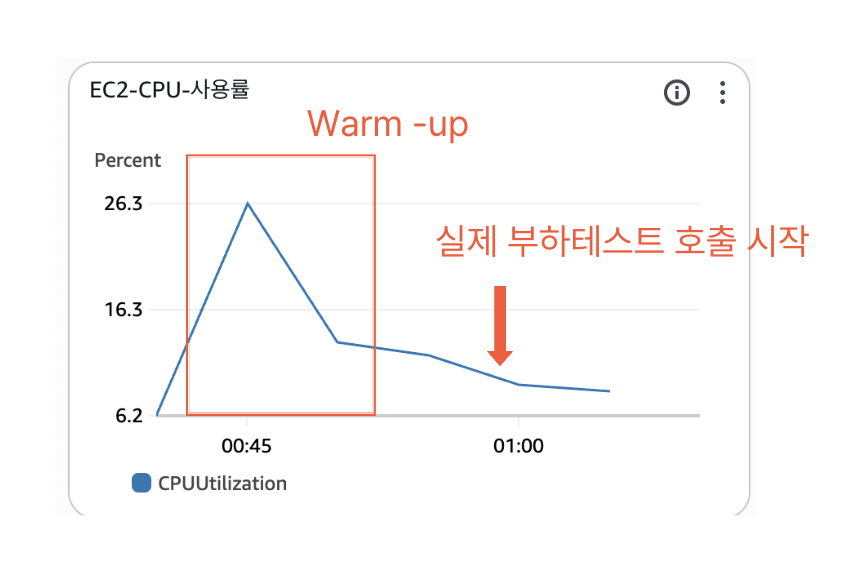
그러자 거짓말처럼 부하테스트 시작과 동시에 CPU 스파이크가 튀지 않았습니다.

또한 top -H로 CPU 리소스 할당 스레드를 살펴본 결과 C2 Compiler가 호출되어 완전히 JVM 컴파일 실행엔진이 최적화된 상황에서 2-10% 내외의 CPU 리소스를 할당받는 모습을 확인할 수 있었습니다.
다음 글에서는 가장 시급한 문제인 Request Failed를 해결한 기록을 다룹니다.
(Odsay API 사용시 10분간격으로 외부 API 호출과정에서 Request Failed가 60%가량 기록되었음)
요약
- 부하테스트 시작과 동시에 CPU 스파이크 발생
- 스레드풀 및 클래스 로딩 문제로 추측하였으나 아니었음
- JIT Compiler 최적화 과정에서 과도한 CPU 리소스 사용문제로 밝혀짐
- C4 Compiler로 최적화되는 호출량을 충족하도록 warm up 코드를 활용하여 CPU 스파이크 해결
Ref)
https://www.baeldung.com/jvm-tiered-compilation
https://dd-developer.tistory.com/129
[오디 -폴링 로직 리팩터링]
1. Warm up Code로 CPU 스파이크 해결하기 feat) JIT Compiler
2. 계정 로드 밸런싱으로 Request Failed를 잡아보자
'프로젝트 > 오디' 카테고리의 다른 글
| [오디 - 폴링 로직 리팩터링] 3. 트랜잭션에서 외부 API를 분리하여 응답 속도를 낮춰보자 (0) | 2025.09.21 |
|---|---|
| [오디 - 폴링 로직 리팩터링] 2. 계정 로드 밸런싱으로 Request Failed를 잡아보자 (0) | 2025.09.21 |
| [오디 - 폴링 로직 리팩터링] 0. 실험 설계 (0) | 2025.09.19 |
| [오디] 회원 전체가 동시에 탈퇴하는 속도 단축하기 feat) 쿼리 최적화 (8) | 2025.08.16 |
| JsonDeserializer 커스텀으로 외부 API 에러 핸들링하기 (0) | 2024.12.22 |



